Original Paper Reference:An Empirical Survey of Data Augmentation for Limited Data Learning in NLP
这篇综述跟之前 NLP DA 综述的区别,abstract 部分说的很清楚:
we provide an empirical survey of recent progress on data augmentation for NLP in the limited labeled data setting, summarizing the landscape of methods (including token-level augmentations, sentence-level augmentations, adversarial augmentations and hidden-space augmentations) and carrying out experiments on 11 datasets covering topics/news classification, inference tasks, paraphrasing tasks, and single-sentence tasks.
主要这篇文章是从多种现有 DA 方法上基于 empirical study 来完成的。文章的行文思路是第二部分介绍在 NLP 领域现有的 DA 方法梳理,第三部分是 DA 一致性训练,第四部分为实验及分析,第五部分介绍了其他有限数据学习方法,第六部分是讨论和未来研究方向。
Introduction
依然是讲存在高质量手工标注数据缺少及语言更新迅速等问题。This highlights a need for learning algorithms that can be trained with a limited amount of labeled data.
文章的贡献点:
(1) summarize and categorize recent methods in textual data augmentation;
(2) compare different data augmentation methods through experiments with limited labeled data in supervised and semi-supervised settings on 11 NLP tasks,
(3) discuss current challenges and future directions of data augmentation, as well as learning with limited data in NLP more broadly.
论文实验的结论是:
no single augmentation works best for every task,
but (i) token-level augmentations work well for supervised learning,
(ii) sentence-level augmentation usually works the best for semisupervised learning,
(iii) augmentation methods can sometimes hurt performance, even in the semi-supervised setting.
Data Augmentation For NLP
这部分主要从 token-level augmentations, sentence-level augmentations, adversarial augmentations and hidden-space augmentations 来分别叙述现有的增强方法。
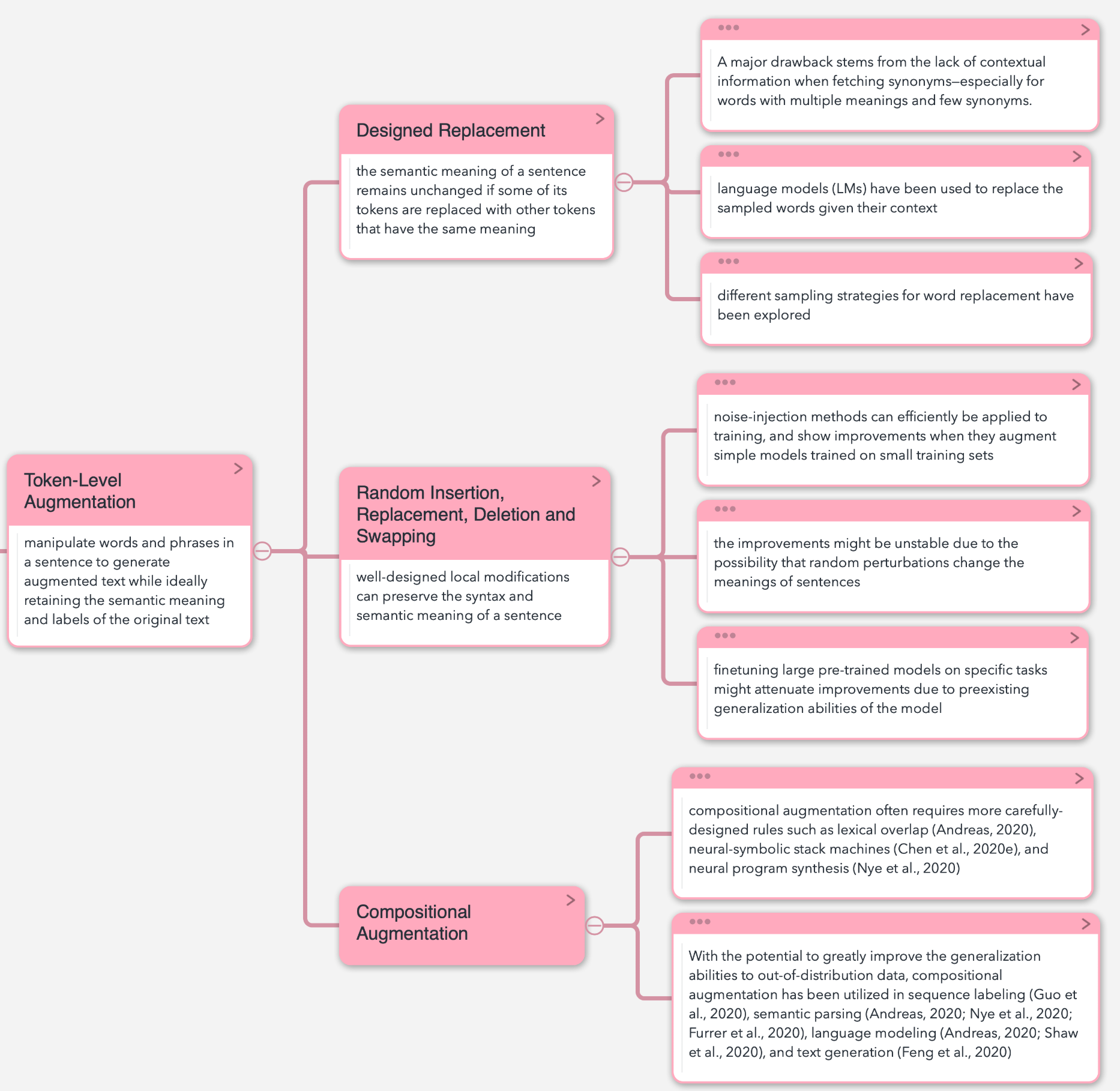
Token-Level Augmentation
主要分三种,一种是设计的替换策略,一种是随机的增删替换,还有则是组合式的增强策略,具体如下图:
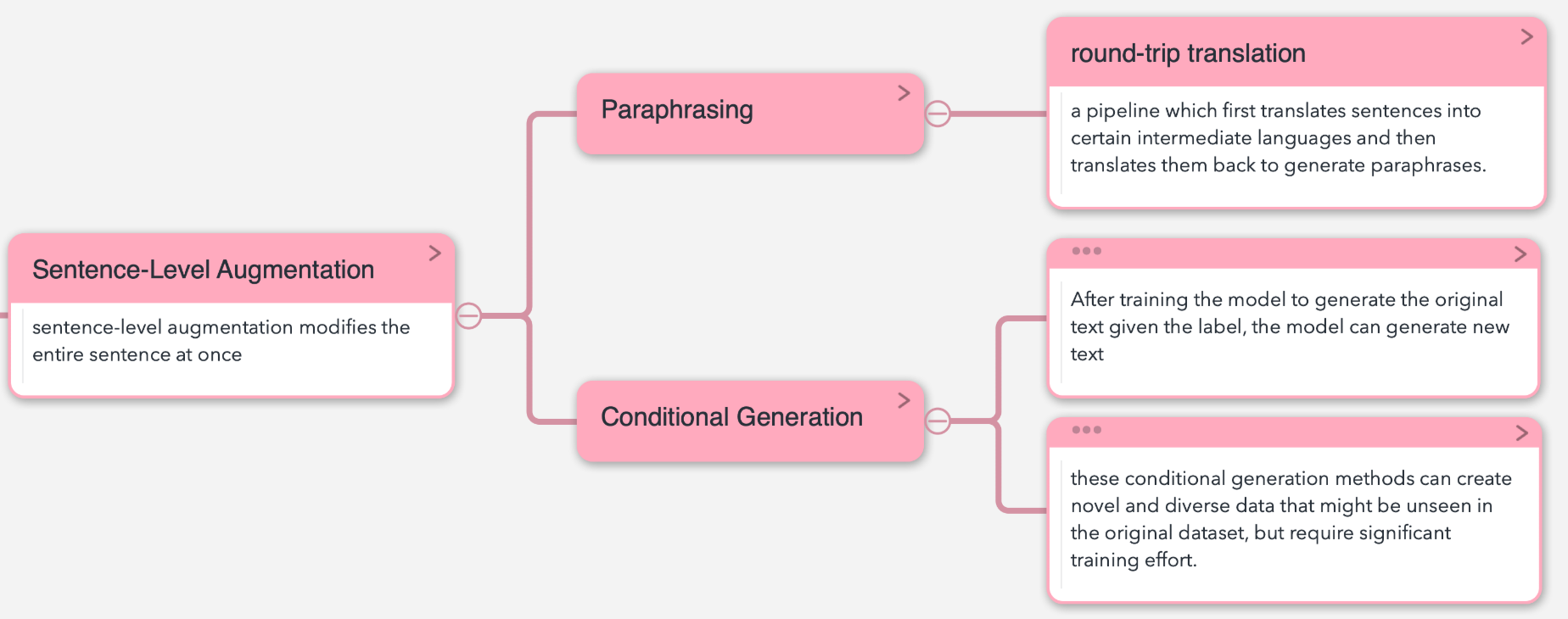
Sentence-Level Augmentation
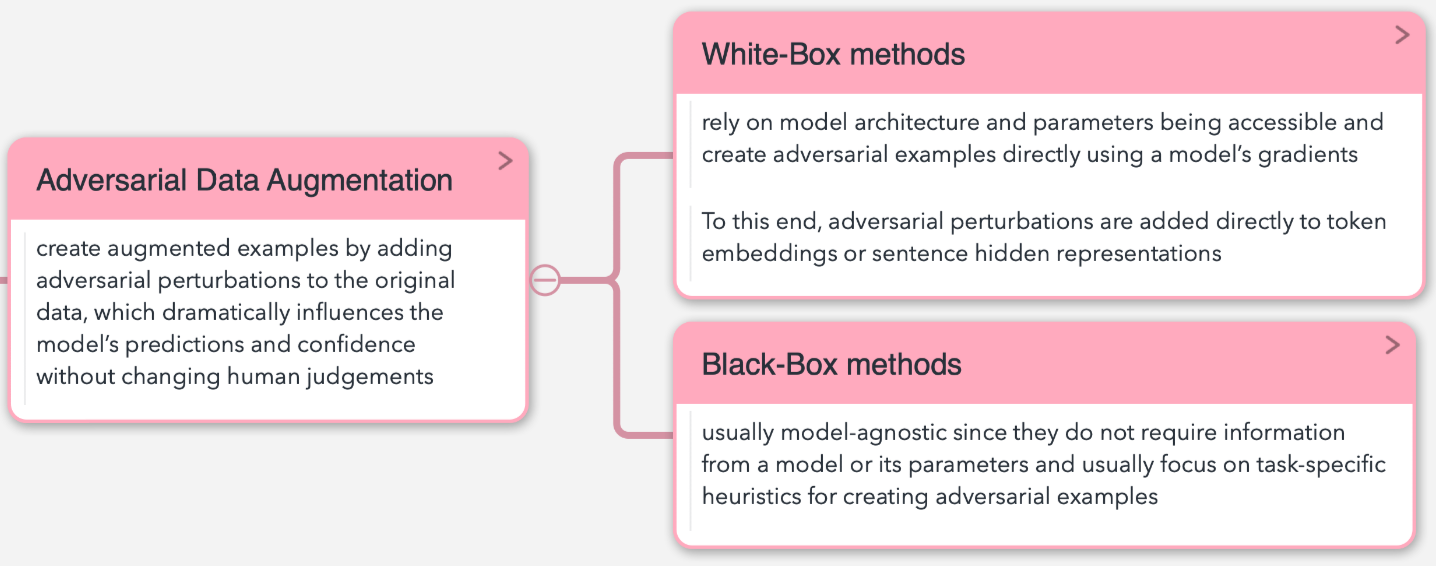
对抗性DA
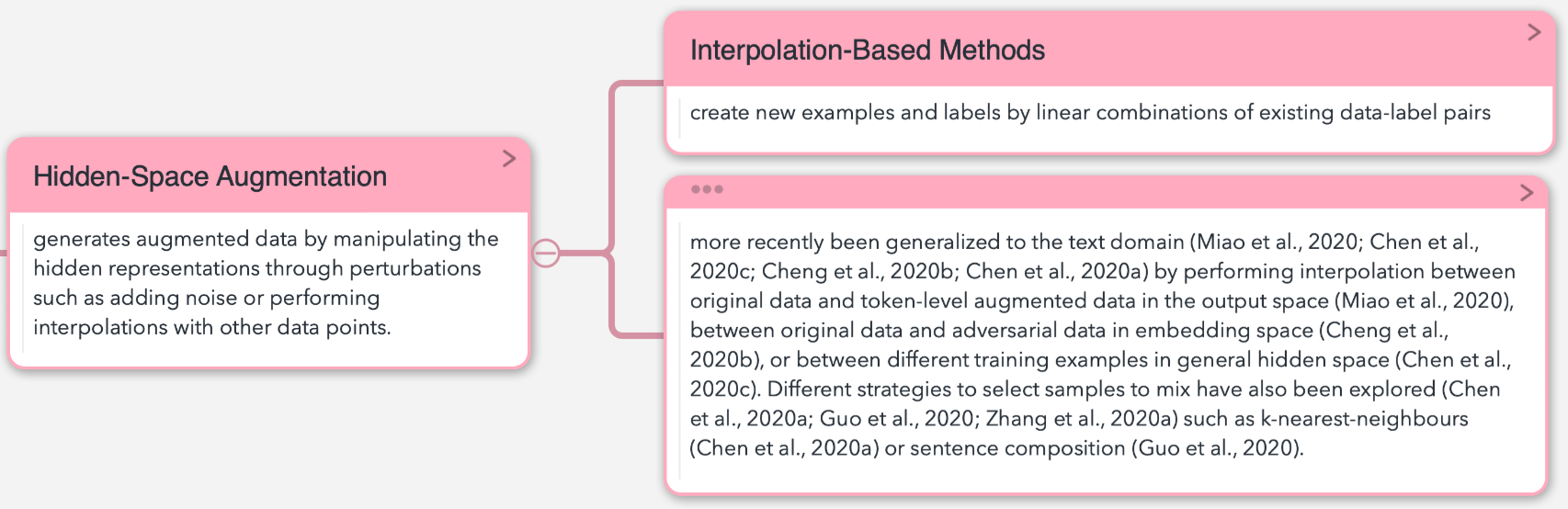
Hidden-Space Augmentation
Consistency Training with DA
这部分主要是介绍关于半监督中 DA 的应用——consistency regularization。其主要是:
regularizes a model by enforcing that its output doesn’t change significantly when the input is perturbed. In practice, the input is perturbed by applying data augmentation, and consistency is enforced through a loss term that measures the difference between the model’s predictions on a clean input and a corresponding perturbed version of the same input.
具体的形式化的描述为 $f_\theta$ be a model with parameters θ,以及$ f_{\hat{\theta}}$ be a fixed copy of the model where no gradients are allowed to flow, $x_l$ be a labeled datapoint with label $y$, $x_u$ be an unlabeled datapoint, and $\alpha(x)$ be a data augmentation method. Then, a typical loss function for consistency training is:
various other measures have been used to minimize the difference between $f_{\hat{\theta}}(x_u)$ and $ f_\theta(\alpha(x_u))$
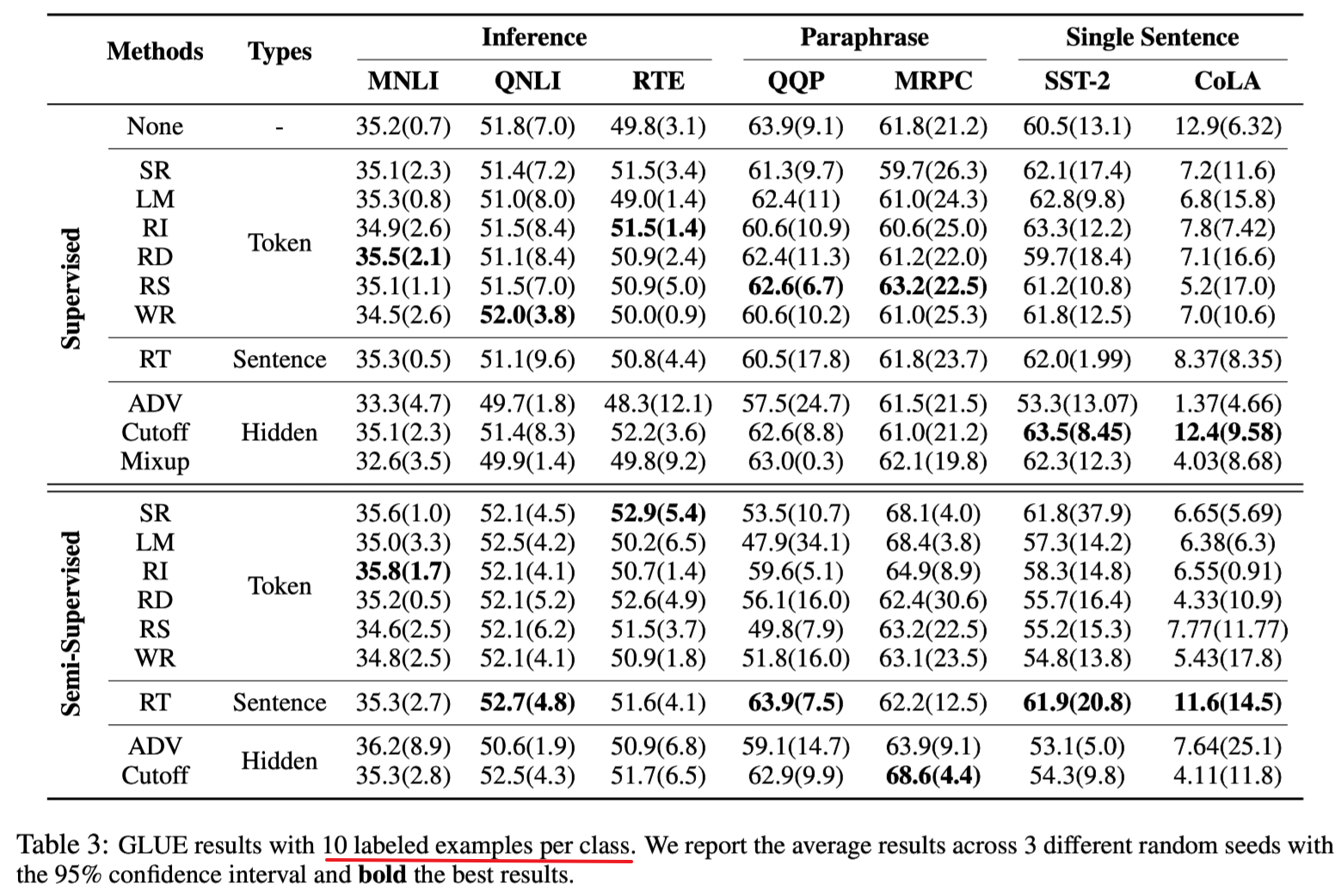
Empirical Experiments
Experiment with 10 labeled data points per class2in a supervised setup, and an additional 5000 unlabeled data points per class in the semi-supervised setup.
Other Limited Data Learning Methods
Low-Resourced Languages 时采用迁移学习方法、Few-shot Learning
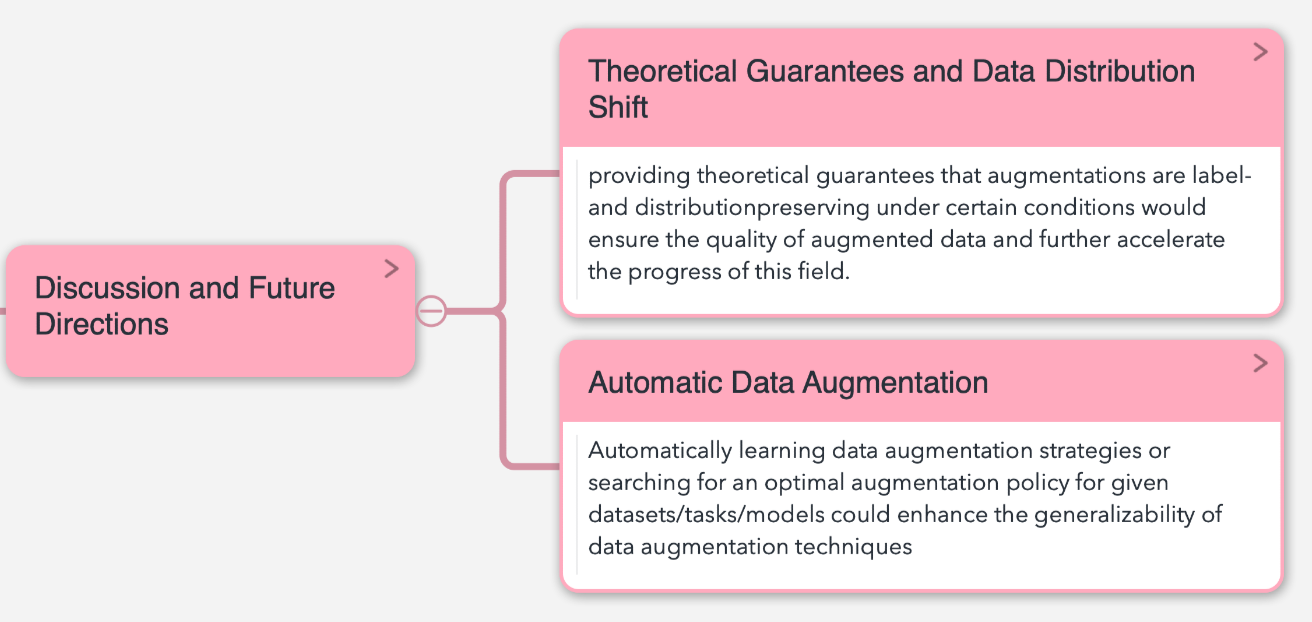
讨论及未来方向
总结
这篇文章对比之前的综述文章,从实验对比角度分析现在的 NLP DA 方法。下一步准备相关 hidden-space Augmentation 的文章仔细读读。

