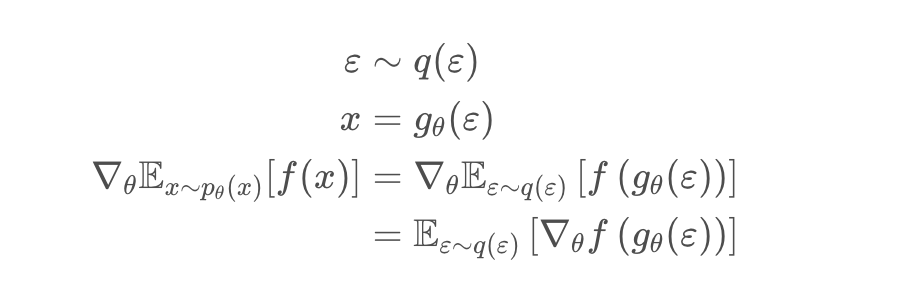算法解释 本文为策略梯度算法实现及详解,策略梯度算法属于蒙特卡洛方法,可以理解为:
算法完成一个回合之后, 再利用这个回合的数据去学习, 做一次更新。因为我们已经获得了整个回合的数据,所以也能够获得每一个步骤的奖励,我们可以很方便地计算每个步骤的未来总奖励,即回报 $G_t$。$G_t$是未来总奖励,代表从这个步骤开始,我们能获得的奖励之和。$G_1$代表我们从第一步开始,往后能够获得的总奖励。$G_2$代表从第二步开始,往后能够获得的总奖励.
我们的目标是求最优策略的最大化奖励:
对其求梯度,进行梯度上升便可以最大化奖励。
利用下面这个公式,对上式求梯度$\nabla \bar{R_\theta}$,最终可以得到这样的结果:
使用蒙特卡洛采样最终为:
这即是策略梯度的核心.
算法实现 代码主要分为三部分, 分为别 agent, model, train. 其中 agent 主要是参数化重采样产生与环境交互的动作和更新策略, model 主要是策略模拟函数, 输入为环境状态, 输出为采取动作的概率分布, 优化的策略参数即是该函数的参数.
策略类 model 的代码如下, 比较简单就不解释了.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import torch.nn as nnimport torch.nn.functional as Fclass MLP (nn.Module): ''' 多层感知机 输入:state维度 输出:概率 ''' def __init__ (self, obs_size, n_actions, hidden_dim = 256 ): super (MLP, self).__init__() self.linear1 = nn.Linear(obs_size, hidden_dim) self.activate = F.relu self.linear2 = nn.Linear(hidden_dim, n_actions) def forward (self, x ): hidden = self.linear1(x) activation = self.activate(hidden) outputs = self.linear2(activation) probs = F.softmax(outputs, dim=0 ) return probs
agent 类 主要是 agent 的解读, 首先是动作选取函数 :
1 2 3 4 5 def choose_action (self,state ): state = torch.from_numpy(state).float () probs = self.policy_net(state) action = np.random.choice(np.array([0 ,1 ]), p=probs.data.numpy()) return action
这里的 Reparameterization 使用的是按照原分布概率进行随机分布采样, 当然也可以按照正态分布,伯努利分布等进行采样.
主要原理为:
我们可以把这里的参数分布$\pi_{\theta}$ , 重写为一个带有噪声变量$\epsilon$的分布,也就是Reparameterization,该变量独立于原来的$\theta$,如下, 其中随机参数分布 $\pi_{\theta}$ 转换为一个噪声分布$q$,$q$可以是标准的正态分布。比如$x$被reparameterize 成从分布$x \sim \mathcal{N}(\mu, \sigma)$中采样,那么: $g_{\theta}(\varepsilon)=\mu_{\theta}+\varepsilon \sigma_{\theta}$,其中$\varepsilon \sim \mathcal{N}$:
其次是更新函数 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 def update (self, transitions ): reward_batch = torch.Tensor(np.array([r for (s,a,r) in transitions])).flip(dims=(0 ,)) state_batch = torch.Tensor(np.array([s for (s,a,r) in transitions])) action_batch = torch.Tensor(np.array([a for (s,a,r) in transitions])) batch_Gvals =[] for i in range (len (transitions)): new_Gval=0 power=0 for j in range (i,len (transitions)): new_Gval=new_Gval+((self.gamma**power)*reward_batch[j]).numpy() power+=1 batch_Gvals.append(new_Gval) expected_returns_batch=torch.FloatTensor(batch_Gvals) expected_returns_batch /= expected_returns_batch.max () pred_batch = self.policy_net(state_batch) prob_batch = pred_batch.gather(dim=1 ,index=action_batch.long().view(-1 ,1 )).squeeze() loss = - torch.sum (torch.log(prob_batch) * expected_returns_batch) self.optimizer.zero_grad() loss.backward() self.optimizer.step()
这里面的核心一个是逆序求回报,其原理为:
计算从这个动作执行以后得到的奖励。因为这场游戏在执行这个动作之前发生的事情是与执行这个动作是没有关系的,所以在执行这个动作之前得到的奖励都不能算是这个动作的贡献。我们把执行这个动作以后发生的所有奖励加起来,才是这个动作真正的贡献, 同时是带有折扣因子的, 奖励衰减
其次是除以最大值进行归一化操作.
之后下面是进行求损失操作, 损失为奖励值, 加上负号进行梯度下降.
最后是 train 函数 , 核心为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 def train (cfg,env,agent ): print ('Start to train!' ) print (f'Env:{cfg.env} , Algorithm:{cfg.algo} , Device:{cfg.device} ' ) rewards = [] score = [] ma_rewards = [] for trajectory in range (cfg.max_trajectories): curr_state = env.reset() ep_reward = 0 done = False transitions = [] for t in range (cfg.horizon): action = agent.choose_action(curr_state) prev_state = curr_state curr_state, reward, done, _ = env.step(action) ep_reward += reward transitions.append((prev_state, action, t+1 )) if done: break score.append(len (transitions)) agent.update(transitions) rewards.append(ep_reward) if ma_rewards: ma_rewards.append( 0.9 *ma_rewards[-1 ]+0.1 *ep_reward) else : ma_rewards.append(ep_reward) if (trajectory+1 ) % 50 == 0 : print ('Trajectory {}\tAverage Score: {:.2f}' .format (trajectory, np.mean(score[-50 :-1 ]))) print ('complete training!' ) return rewards, ma_rewards, score
注释很详细, 不再赘述.