Original Paper Reference:MixText: Linguistically-Informed Interpolation of Hidden Space for Semi-Supervised Text Classification (Chen et al., ACL 2020)
论文主要借鉴了 MixUP 的思想,mixup 论文阅读记录 | SuooL’s Blog,提出了一种在 hidden space 进行文本数据增强的方法,并在此基础上提出了一个半监督学习文本分类的框架。使用数据增强的方法为无标签数据估计低熵标签。通过混合标签数据、无标签数据和增强数据,MixText在一系列文本分类任务上取得了很好的效果。
本质上该文章属于各种现有方法在文本领域的应用,创新是在 hidden space 进行 DA,并用现有的一些技术组合构建了一个半监督的文本分类方法。
Introduction
已有的半监督文本分类方法可以分为以下几类:
使用VAEs重构句子并预测句子标签;
促使模型在无标注数据上输出预测用于自学习;
在加入对抗噪声或数据增强后,进行一致性训练;
使用无标注数据进行大规模的预训练,然后使用标注数据微调。
已有工作的不足:
大多数已有工作将标注数据和无标注数据区分对待,也就是监督信息不能从标注数据转移到无标注数据,反之亦然。因此,大多数半监督模型很容易在非常有限的标注数据上过拟合,尽管无标注数据是充足的。
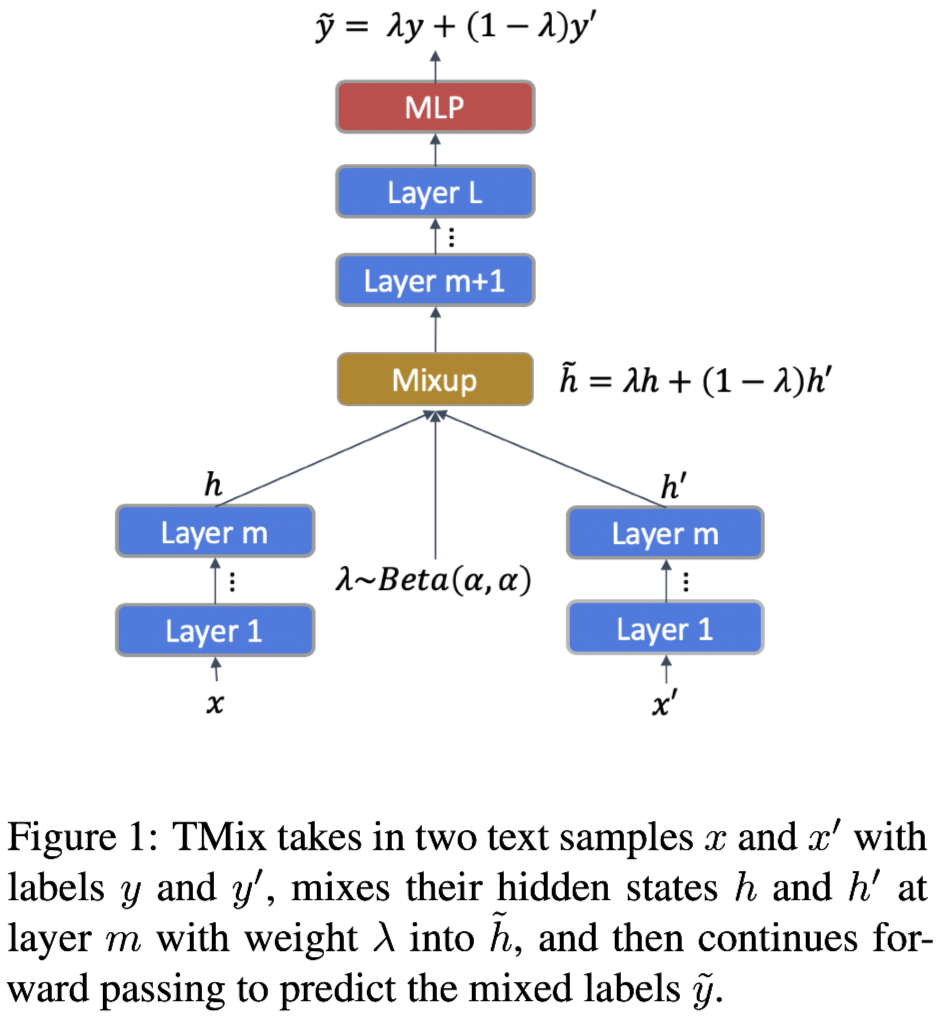
为了解决上述问题,受图像分类的 Mixup 等方法的启发,本文提出了新的数据增强方法TMix,如上图所示,向 TMix 输入两个文本实例,并在模型的某一 hidden layer 进行插值增强,因此该方法 TMix 有潜力创建无限数量的新扩增数据样本,极大地避免了过拟合问题。
同时基于TMix,作者提出了用于文本分类的半监督学习模型 MixText 来建模标注样本和无标注样本间的关联,克服了上述的其他半监督模型的局限性。
MixText首先为无标注数据预测低熵的标签,然后使用TMix插入标签数据和无标签数据。MixText可以挖掘句子之间的隐式关联,并在有标签的句子上进行学习时利用无标注的句子信息。同时,MixText利用了一些半监督学习的方法以进一步利用无标注的数据,包括 self-target-prediction、entropy minimization和consistency regularization。
相关工作
预训练及微调框架
文本数据的半监督学习
Interpolation-based Regularizers
这类方法(例如Mixup)被提出应用于图像数据的有监督学习和半监督学习,并在图像分类等任务上实现了SOTA的效果。简单来说是将两张输入图像重叠并组合图像的标签,作为虚拟训练数据。也有学者设计了这类方法的变形,例如在输入空间进行插值,在隐藏空间表示进行插值。但是这些插值方法还没有应用于NLP领域,因为大多数文本的输入空间是离散的,例如one-hot向量,和图像中连续的RGB数值不同,此外,文本在结构上更加复杂。
- 文本的数据增强
这部分内容之前已有综述阅读记录:
自然语言处理NLP数据增强综述阅读记录 | SuooL’s Blog
论文阅读 An Empirical Survey of Data Augmentation for Limited Data Learning in NLP | SuooL’s Blog
TMix
作者这里直接说扩展基于用于图像的Mixup方法应用在文本建模上。
Mixup的核心思想:给定两个有标注的数据点 $(x_i, y_i), (x_j, y_j)$,其中 $x$ 是图像,$y$ 是标签的one-hot表示。通过如下的线性插值构造虚拟的训练样本,其具体原理和方法见上文,这里不再赘述。利用新构造的虚拟训练样本可用于训练神经网络模型。从结果上看,Mixup可以有多种解释:
- Mixup可以视为一种数据增强方法,也就是基于原始的训练集构造新的数据样本;
- Mixup强迫模型进行规范化,以实现在训练数据间的线性表现。
Mixup在连续的图像数据上有着较好的效果,然而将其扩展到文本是很有挑战性的,因为计算离散token的插值是不可行的。
将Mixup扩展到文本领域
为解决上述在文本数据上进行插值的挑战,作者提出了interpolation in textual hidden space 的方式。首先,作者使用多层的模型例如 BERT 对句子进行编码。已有工作从两个隐藏向量的插值解码,生成混合了两个原始句子信息的新句子。受此工作启发,作者提出在隐藏空间进行插值作为文本的数据增强方法。对于有$L$层的编码器,对第 $m$-th层的隐藏表示进行混合,$m\in [0, L]$。
如上图所示,首先在底层分别计算两个文本的隐藏表示,然后在$m$层混合隐藏表示,接着将插值过后的隐藏表示输入给上层。
Mathematically, denote the $l$-th layer in the encoder network as $g_l(.; θ)$, hence the hidden representation of the $l$-th layer can be computed as $h_l= g_l(h_{l−1}; θ)$. For two text samples $\bf{x}_i$and $\bf{x}_j$, define the 0-th layer as the embedding layer, i.e., $h^i_0= W_E\bf{x}_i$, $h^j_0= W_E\bf{x}_j$, then the hidden representations of the two samples from the lower layers are:
两个样本在低层的隐藏表示为:
在第$m$层的混合以及继续向上层传递定义为:
上述方法就称为TMix,将整个mixup操作定义成下式并得到$\tilde{h}_L$.
和原始的 Mixup 相对比,TMix 依赖于编码器,因此插值计算的范围更广阔。为了简化,接下来将TMix形式化为 $TMix(x_i, x_j)$
在实验中,每个batch都从Beta分布中采样混合参数$\lambda$以进行插值,其中$\alpha$是控制$\lambda$分布的超参数:
TMix在标签的混合上也采用 mixup 中的方法,然后使用$(\tilde{h}_L, \tilde{y})$.
mixup哪层的隐藏表示是值得研究的问题。本文的实验中使用12层的BERT-base作为编码器。已有研究表明了BERT的不同层具有不同的表示能力。基于这些发现,作者使用同时包含了句法和语义信息的层作为混合层,即$M={7,9,12}$。对于每个batch,从$M$中随机采样$m$作为混合层的层数。
文本分类
TMix提供了一种通用的文本数据增强的方法,可以用于任意的下游任务中,本文只关注于文本分类任务。最小化混合标签和分类器预测的概率之间的$KL$散度作为损失:
其中$p(,: \phi)$是编码器上方的分类器。本文的实验中分类器是一个2层的MLP, 使用$TMix(\bf(x)_i, \bf(x)_j)$作为输入,并输出一个概率向量. 模型同时优化编码器参数和分类器参数.
半监督 MixText
本节介绍如何使用TMix进行半监督学习。给定一个有限的带有标签的文本集合$X_l = \{x^l_1, …, x^l_n\}$ 和标签集合 $Y_l = \{y^l_1, …, y^l_n\}$,以及大规模的无标签文本集合 $X_u = \{x^u_1, …, x^u_m\}$。目标是有效地利用标注数据和无标注数据,学习得到分类器。
本文提出文本半监督学习框架MixText。核心思想是在有标签数据和无标签数据上利用TMix,以实现半监督学习。
作者提出标签猜测的方法,为无标签的数据猜测出一个标签,从而将这些无标签数据作为附加的标签数据,进行TMix后用于训练。此外,作者还将其他的数据增强技巧和TMix相结合,以生成大量的增强数据。最后,使用熵最小损失优化模型,鼓励模型在无标签样本上分配更加尖锐的概率分布。整体架构如图所示。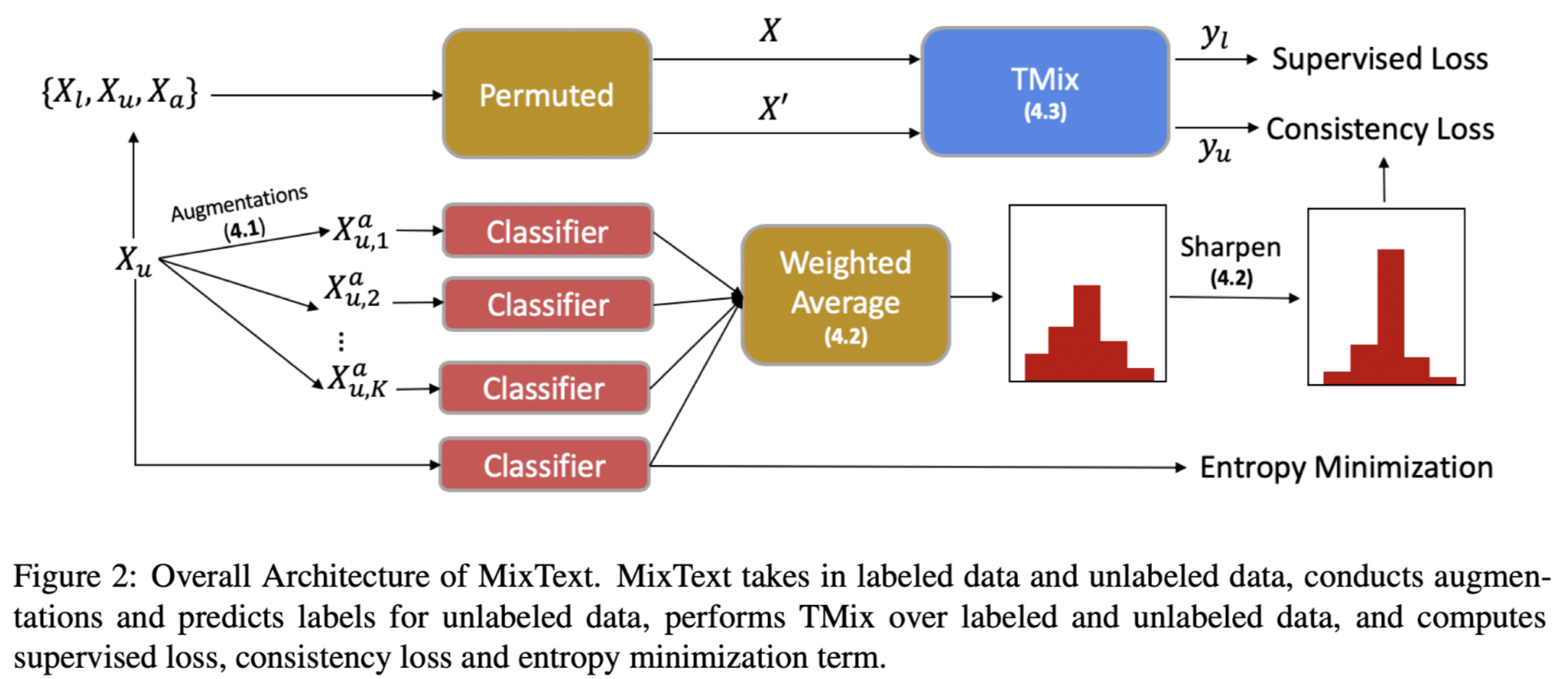
数据增强
使用back translation对无标签数据进行重写。对于无标签文本集合$X_u$中的每个$x^u_i$,通过back translation并设置不同的中间语言,生成$K$个增强样本$x^a_{i, k} = augment_k(x^u_i), k\in [1, K]$。在增强文本的生成过程中,使用随机采样而不是beam搜索,以保证多样性。这些增强样本将被用于为无标签数据生成标签,接下来将详细介绍。
标签猜测
给定一个无标签数据样本$x^u_i$和他的$K$个增强样本$x^a_{i, k}$,使用如下的公式生成标签:
加权平均可能使得预测出的标签比较均衡,为了避免这一问题,使用如下的锐化函数让标签的分布更尖锐一些。其中$T$是超参数,当 $T\rightarrow 0$时,生成的标签就是one-hot向量。
TMix on Labeled and Unlabeled Data
为无标签样本生成标签后,将有标签文本、无标签文本和无标签增强文本合并成一个大集合: $X = X_l \cup X_u\cup X_a, Y = Y_l\cup Y_u\cup Y_a$。其中$Y_a = \{y^a_{i, k}\}$,作者定义$y^a_{i, k} = y^u_i$。在训练时,随机采样两个数据点$x, x^{‘} \in X$,然后计算$TMix(x, x^{‘} ), mix(y, y^{‘} )$,并使用KL散度作为损失:
由于两个样本点是从$X$中随机采样的,我们可以从不同的类别插值文本:混合有标签数据、混合有标签数据和无标签数据、混合无标签数据,基于样本的类型,损失可以划分为两类:
- 有监督损失
当$x\in X_l$时,我们使用的大部分信息来自于有标签数据,因此使用有监督损失训练模型。
- 一致性损失
当样本来自于无标签集合或者增强集合,即$x\in X^u\cup X^a$,大多数信息来自于无标签数据。KL散度是一致性损失的一种。
Entropy Minimization
为了促使模型为无标签数据生成可信的标签,作者提出最小化预测概率的熵值作为自学习损失:
MixText最终的目标函数为:
实验
数据集: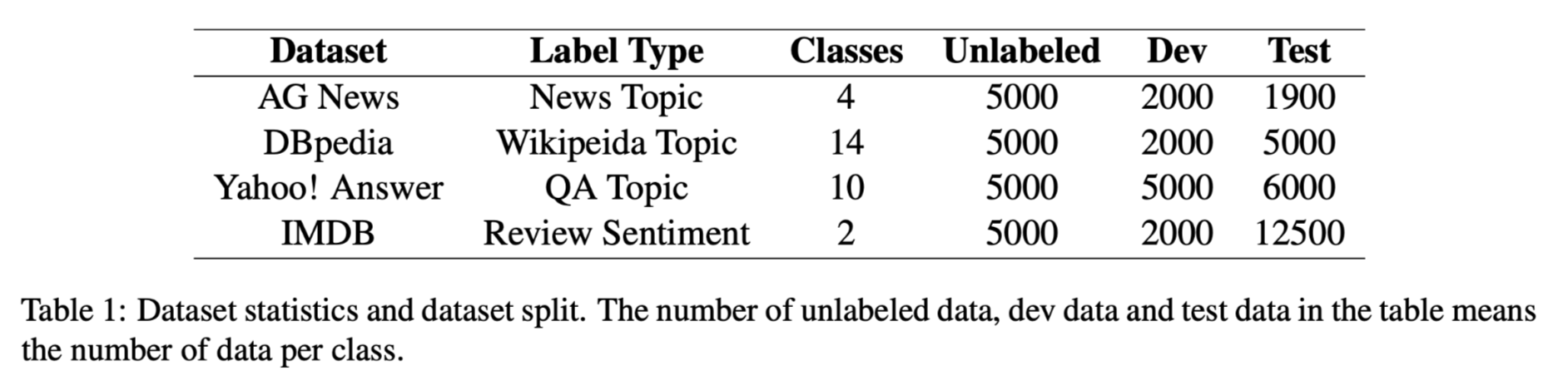
实验设置:
used BERT-based-uncased tokenizer to tokenize the text, bert-based-uncased model as our text encoder, and used average pooling over the output of the encoder, a two-layer MLP with a 128 hidden size and tanh as its activation function to predict the labels. The max sentence length is set as 256. We remained the first 256 tokens for sentences that exceed the limit. The learning rate is 1e-5 for BERT encoder, 1e-3 for MLP. For α in the beta distribution, generally, when labeled data is fewer than 100 per class, α is set as 2 or 16, as larger α is more likely to generate λ around 0.5, thus creating “newer” data as data augmentations; when labeled data is more than 200 per class, αis set to 0.2 or 0.4, as smaller α is more likely to generate λ around 0.1, thus creating “similar” data as adding noise regularization.
实验结果: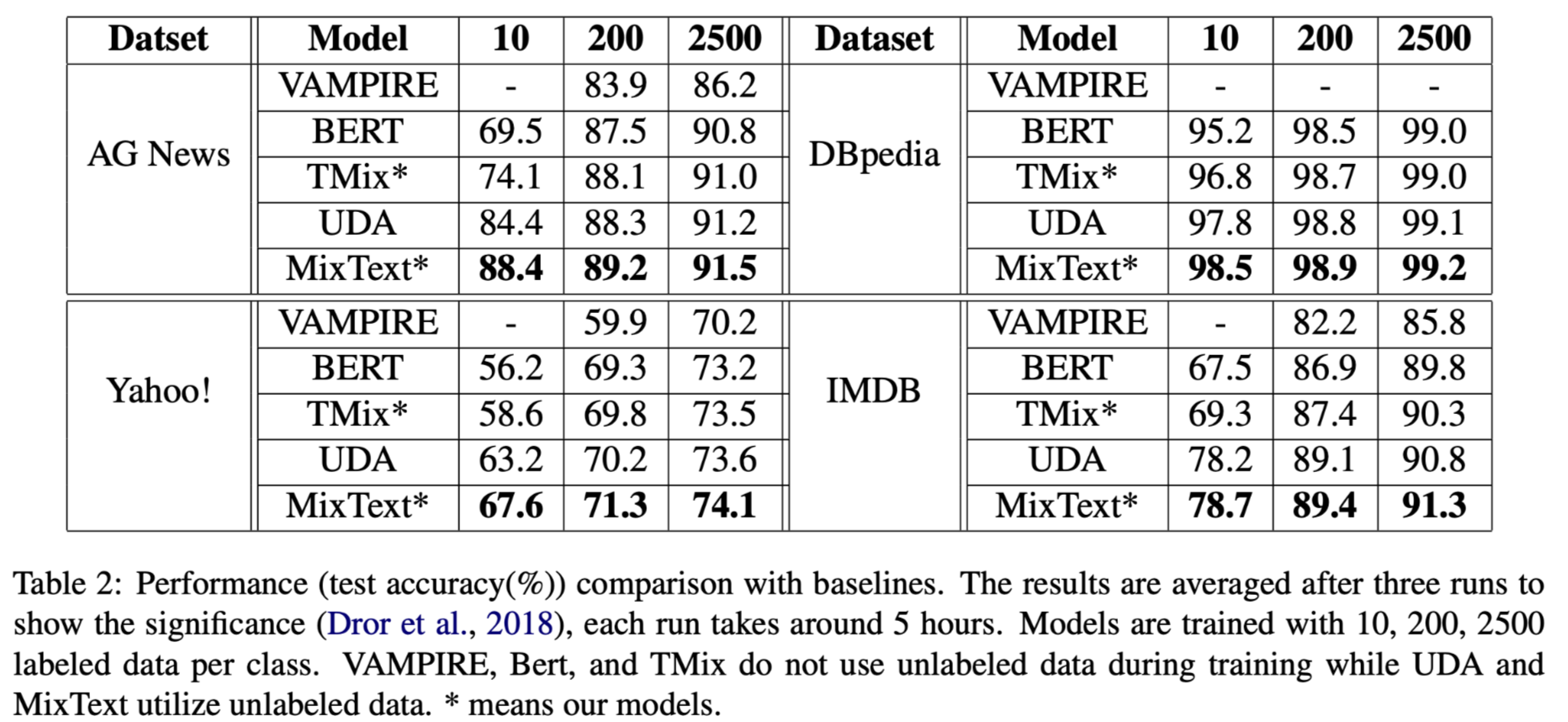
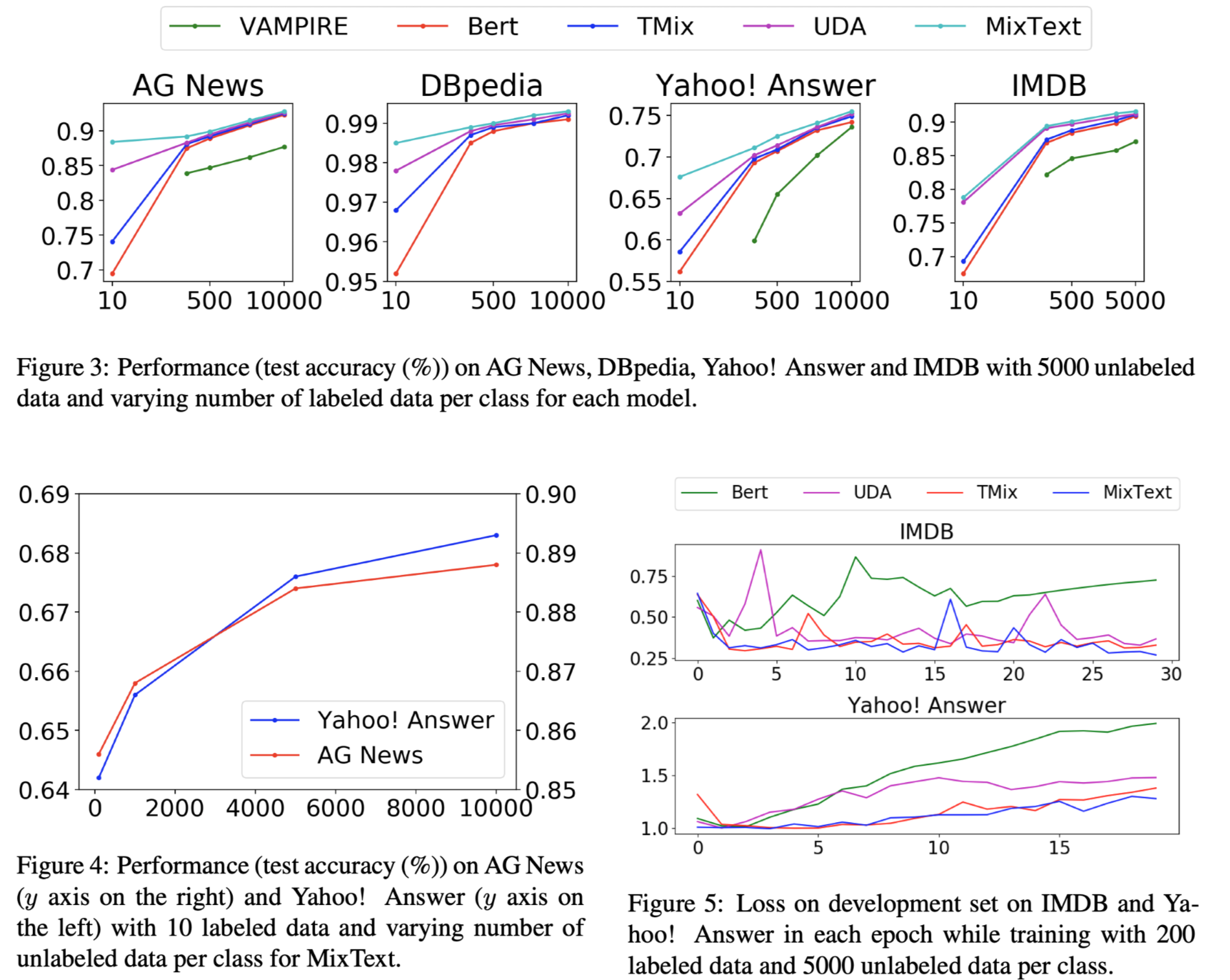
消融实验结果: