Original Paper Reference:[1906.08988] A Fourier Perspective on Model Robustness in Computer Vision, NIPS 2019
这篇文章是从频域角度来分析模型的鲁棒性,为审视模型鲁棒性提供了一个新的角度。
Introduction
作者首先叙述论文的 motivation,即是 deep neural models lack the robustness of the human vision system when the train and test distributions differ,同时 DA 作为一种提高模型鲁棒性的有效方法已被广泛验证其有效性,但是 DA 对于模型鲁棒性增益的原因和表现存在不可解释性,具体表现在不同的 DA 方法的鲁棒性增益不同,不同的数据 corruption 的模型鲁棒性增益表现也不同,同时模型的泛化性和鲁棒性的 trade-off 也缺乏一个统一的解释框架。
针对当前 DA 研究成果中的一些共性现象,observed that Gaussian data augmentation and adversarial training improve robustness to noise and blurring corruptions on the CIFAR-10-C and ImageNet-C common corruption benchmarks, while significantly degrading performance on the fog and contrast corruptions,即是针对不同的数据 corruptions,鲁棒性表现出统一的规律。从而引出了一个自然的问题:
What is different about the corruptions for which augmentation strategies improve performance vs. those which performance is degraded?
作者假设:hypothesis is that the frequency information of these different corruptions offers an explanation of many of these observed trade-offs,并通过在傅里叶频域中应用扰动,证明了这两种增强策略使模型偏向于利用输入中的低频信息,这种低频偏差导致了模型对高频信息中的 corruption 更具鲁棒性,同时若 corruption 出现在低频信息中,则模型鲁棒性降低。
从而作者的研究说明:more diverse data augmentation procedures could be leveraged to mitigate these observed trade-offs, and indeed this appears to be true.
Preliminaries设定

用参数 $\sigma$ 定义高斯数据增强:在每次迭代中,在输入图像的每个像素点上增加高斯噪声$\mathcal{N}\left(0, \widetilde{\sigma}^{2}\right)$,其中 $\widetilde \sigma^2$ 是从 $[0,\sigma]$ 中随机均匀选择的。实验中,Cifar-10上的评估 $\sigma=0.1$,骨干网络选用 Wide ResNet-28-10;ImageNet 上的评估 $\sigma=0.4$,骨干网络选用ResNet-50。另外,基础的数据增强方法有翻转和裁剪。
Fourier heat map:在傅里叶频域中分析模型对高频和低频扰动的敏感性。令 $U_{i,j} \in \mathbb R^{d_1 \times d_2}$ 为实值矩阵,使得$||U_{i,j}|=1|$ ,$\mathcal F(U_{i,j})$最多只有两个非零元素位于 $(i, j)$,称这些矩阵为傅里叶基矩阵。
给定一个模型和一副验证图像 $X$,可以生成带有傅里叶基噪声(加性噪声)的扰动图像:通过计算 $\widetilde X_{i,j}=X + rvU_{i,j}$ 其中 $r$ 为从$\{-1,1\}$ 中随机均匀选择的, $v>0$ 是扰动的范数。对于多通道图像,对每个通道执行同样的扰动操作。之后,可以利用傅里叶基噪声评估该模型,并可视化测试误差如何作为$(i,j)$的函数变化,将测试误差的可视化结果称为模型的傅里叶热图。
鲁棒性问题
鲁棒性问题,从问题本身而言不难理解,但是从解释的角度出发却几乎没有相关的成果,为何模型在 IID 的训练和测试集上表现的非常不错,然而当测试数据出现轻微的扰动的时候其表现却变得非常不可靠?这个问题本身就是鲁棒性不足的表现,是模型对于数据特征分布理解和学习不足的结果,也可能是模型过于片面的依赖某一特征导致的结果。模型的脆弱表现跟训练数据显然有关系,其无法应对自然发生的无法期待的非稳健的数据变化。
在图像域中,输入和目标之间存在大量相关性。简单的统计数据,如颜色、局部纹理、形状,甚至非直观的高频模式,都可以在某种程度上实现显著的 IID 特征泛化,从而为模型所学习和记忆。为了证明这一点,作者对 ImageNet 模型进行了训练和测试,在频域中对输入进行了严格过滤。虽然适度过滤当前已用于模型压缩,但为了测试模型泛化的局限性,作者尝试了极端过滤。结果如下图所示。当应用低频滤波时,越低的滤波变换使得图像看起来是越模糊不清,颜色变化连续平缓,看起来像是一团颜色的混合,此时模型也可以达到30%以上的测试精度。更令人震惊的是,模型在严重的高频滤波下,此时模型几乎只剩下类似纹理的特种,颜色缺失严重,但模型依然使用了人类几乎看不见的高频特征,实现了50%的准确率。必须将像素统计数据标准化为单位方差,才可以使这些高频特征可视化。鉴于这些类型的特征对于泛化很有用,所以模型利用这些非稳健统计数据就不足为奇了。
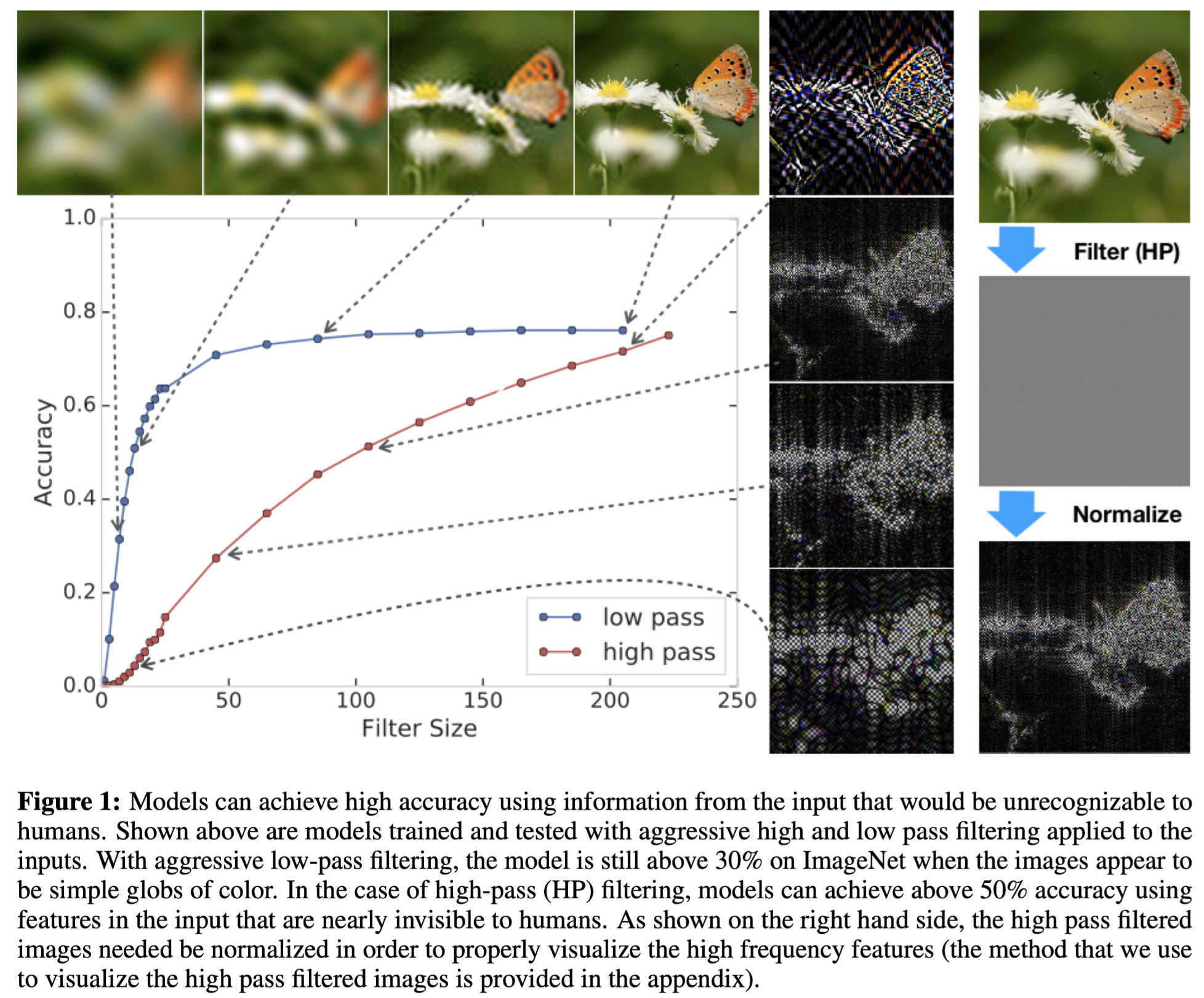
Trade-off and correlation between corruptions: a Fourier perspective
上述的实验证实,不管低频还是高频特种对于模型分类预测均有重要作用,因此一个自然的假设是不同的 DA 方法使模型偏向于某一种特种的学习利用,而模型最终使用的特征决定了模型的鲁棒性表现,作者采用了傅里叶视角的来研究比较不同的 DA 方法在数据corruption 时其鲁棒性的权衡和相关性表现。
Gaussian data augmentation and adversarial training bias models towards low frequency information
这一节主要是说明针对低频信息的高斯数据增强和对抗训练偏差模型。
已有研究发现,在 CIFAR-10-C 数据集上,三种不同的模型表现:自然训练模型、高斯增强模型、对抗训练模型。其中高斯数据增强和对抗训练提升了模型对所有噪声和大部分模糊扰动的鲁棒性,然而对雾化和对比度调整的鲁棒性大幅下降。
这其中的鲁棒性表现权衡作者假设可以通过傅里叶频谱进行分析解释。用 $C: \mathbb R^{d_1 \times d_2} \rightarrow \mathbb R^{d_1 \times d_2}$ 表示扰动函数。下图为自然图像的傅里叶谱以及常见扰动的平均增量可视化图。能够观察到,自然图像在低频中具有更高的浓度 (concentrations)。高斯噪声在傅里叶频率上表现为均匀分布,因此相对于自然图像具有更高的频率统计。另外,许多模糊类的扰动移除或改变了图像的高频内容,因此,$C(X)-X$ 将具有更高比例的高频能量。对于对比度和雾化扰动,损坏的能量更多集中于低频分量上。

这些傅里叶谱的观察说明,这两种数据增强方法鼓励模型在面对高频信息的时候更具有稳定性,同时更依赖低频信息,因此当面对 fog 和 contrast 这种改变数据低频信息分布的 DA 操作时,模型表现会比较差。
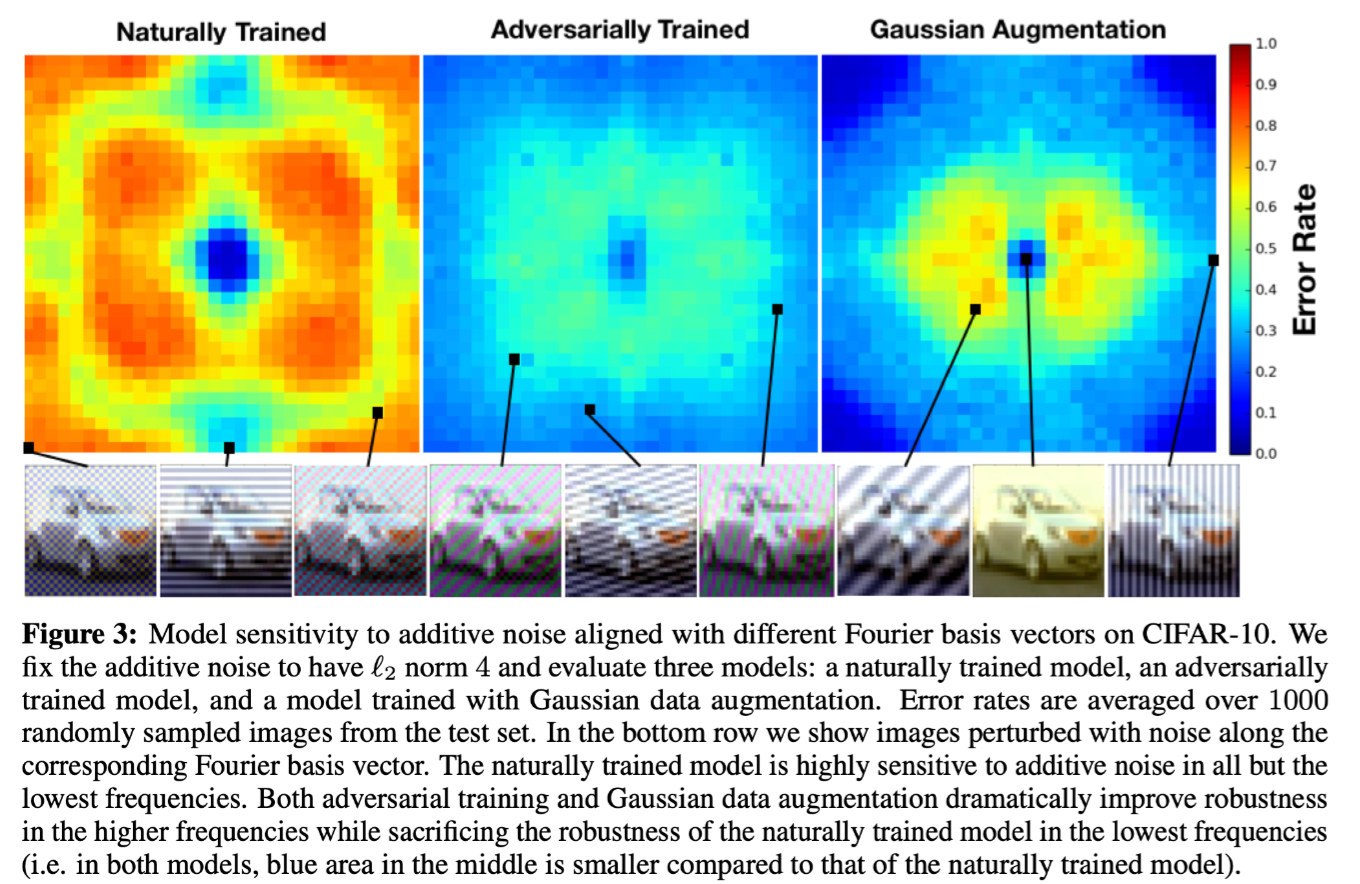
作者通过实验验证了这一假设。首先测试对各个 Fourier 基向量扰动的模型敏感性。具体结果如下图。(加性噪声固定为 $\ell_2$ 范数4,底部图像为扰动后的图像,指标为 Error Rate,表示分类错误的样本占总样本数的比例),能够观察到,自然训练的模型对除最低频之外的所有加性扰动都高度敏感,而高斯数据增强和对抗训练都显着提高了模型对较高频率的鲁棒性,同时牺牲自然训练模型在最低频率下的鲁棒性(表现为,对抗训练和高斯数据增强的模型中,中间的蓝色区域相对于自然训练的模型更小)。
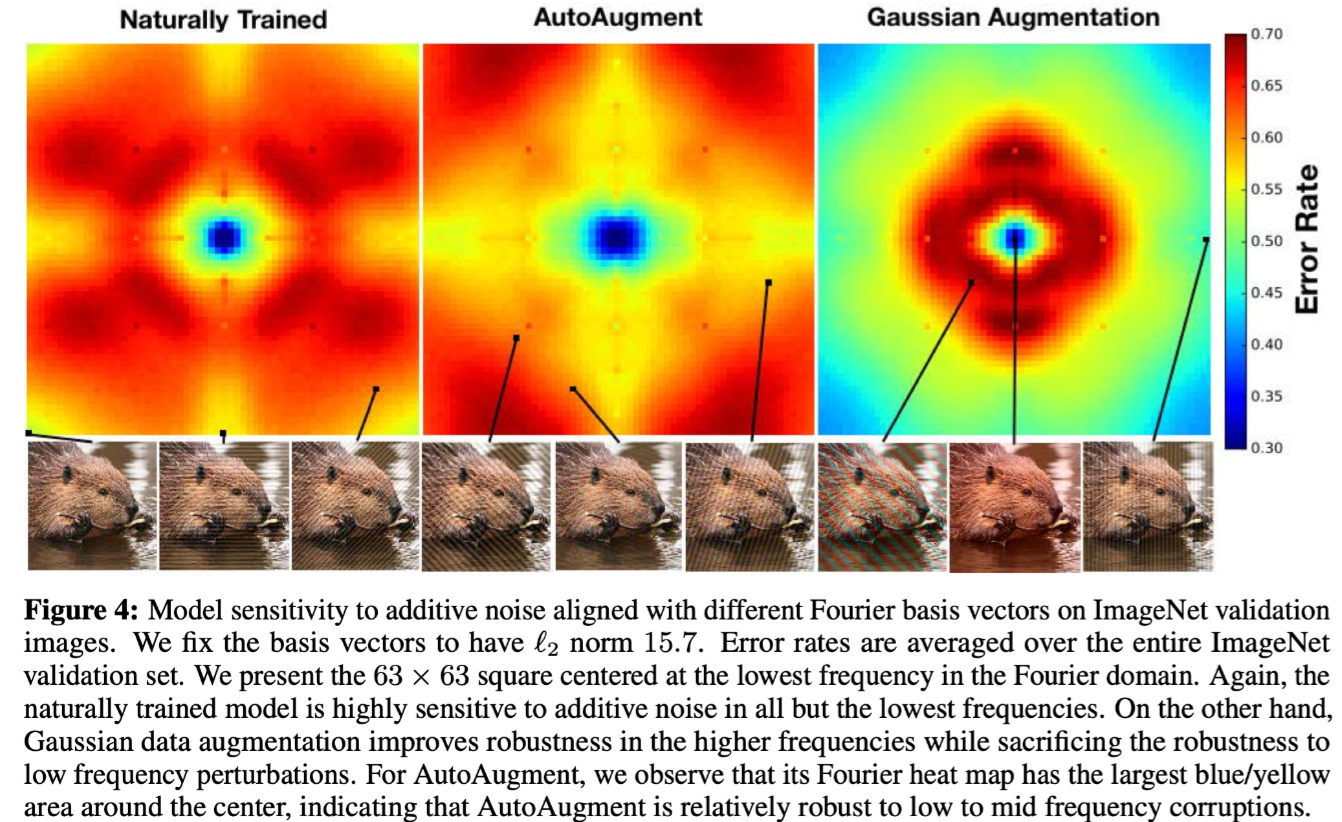
在 ImageNet 上的评估结果如下图(基向量固定为 $ \ell_2$ 范数15.7,错误率在整个验证集上取平均值),结果与 CIFAR-10 上类似,自然训练的模型对除最低频率之外的所有加性噪声都高度敏感,高斯数据增强提高了模型对高频扰动的鲁棒性,同时减少了对低频扰动的性能。对于AutoAgument,其傅里叶热图在中心周围具有最大的蓝色/黄色区域,这表明其对中低频扰动相对稳健。
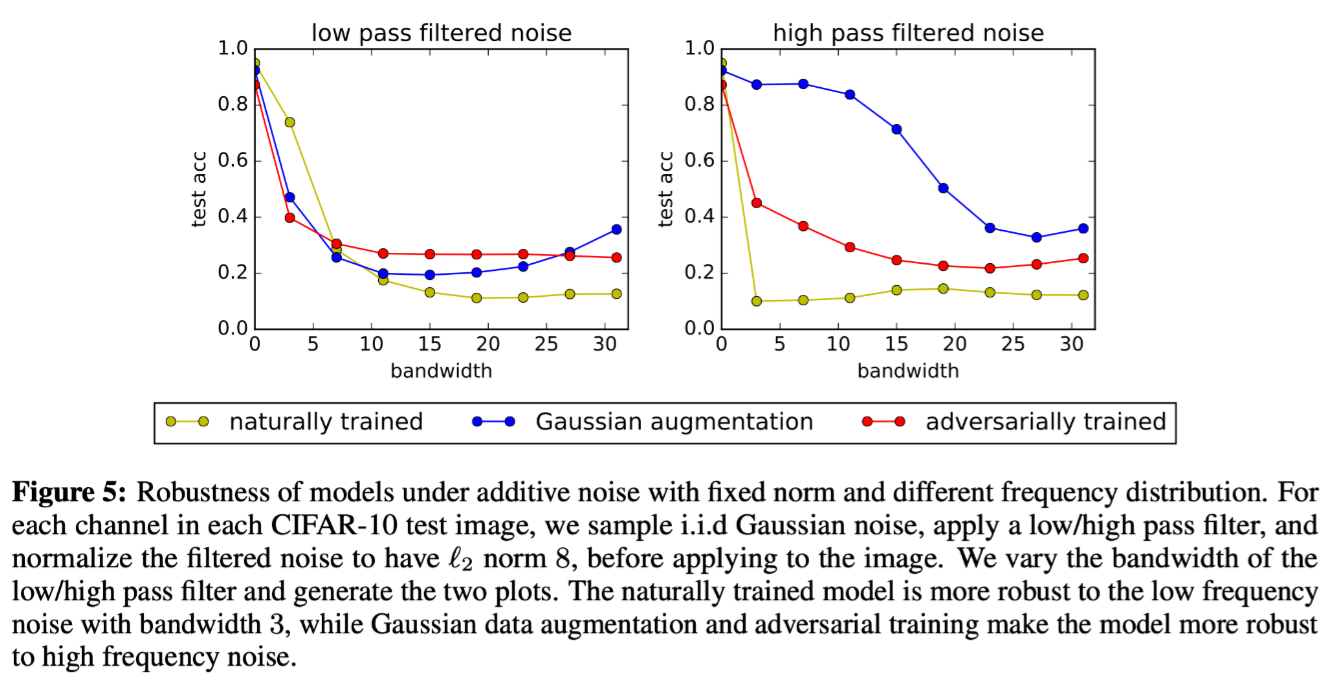
为进一步测试,添加具有固定$\ell_2$范数但以原点为中心的不同频率带宽的噪声。考虑两个设定:一种是原点以最低频率为中心,另一种是原点以最高频率为中心。结果如下图所示(对 IID 高斯噪声进行采样,应用低/高通滤波器,并将滤波后的噪声归一化为 $\ell_2$ 范数8,然后再加到输入图像上,即对噪声进行滤波),对于大小为3的低频中心带宽,自然训练的模型错误率不到其他模型的一半,且对低频噪声更加鲁棒。对于高频带宽,使用数据增强训练的模型性能显着优于自然训练的模型,对高频噪声更加鲁棒。这也证明了使用噪声增强训练的模型更依赖低频信息的假设一致。(即,模型的判决更加依赖于低频信息,高频信息被扰动了也无关)
最后一组测试,对输入图像应用低/高通滤波后评估模型的性能。与前面的实验一致,作者发现应用低通滤波后会降低雾化和对比度扰动的性能,同时提高加性噪声和模型扰动的性能。如果应用高通滤波器则会观察到相反的结果,应用高通滤波器会降低所有扰动的性能,高频扰动的性能下降更加严重。
最终为了量化这一表现,To better quantify the relationship between frequency and robustness for various models we measure the ratio of energy in the high and low frequency domain.具体为:
对于每个扰动 $C$,在扰动的增量 (即 $C(X)-X$) 上应用带宽为27的高通滤波 (用 $H(·)$ 表示此操作),使用 $\frac{|H(C(X)-X)|^{2}}{|C(X)-X|^{2}} $ 作为衡量扰动中高频能量比例的指标。在CIFAR-10-C 上评估 6 个模型:自然训练、高斯数据增强训练、对抗训练、带宽15的低通滤波训练、带宽31的高通滤波训练、使用AutoAugment数据增强训练。结果如下图所示(x轴表示扰动类型的高频能量分数,y轴表示与自然训练模型相比测试精度的变化,底部的图例为每条拟合直线的斜率k和差值r),能够观察到,高斯数据增强、对抗训练和低通滤波器训练提高了模型对高频损坏的鲁棒性,并降低对低频损坏的鲁棒性。AutoAugment提高了几乎所有扰动的鲁棒性。
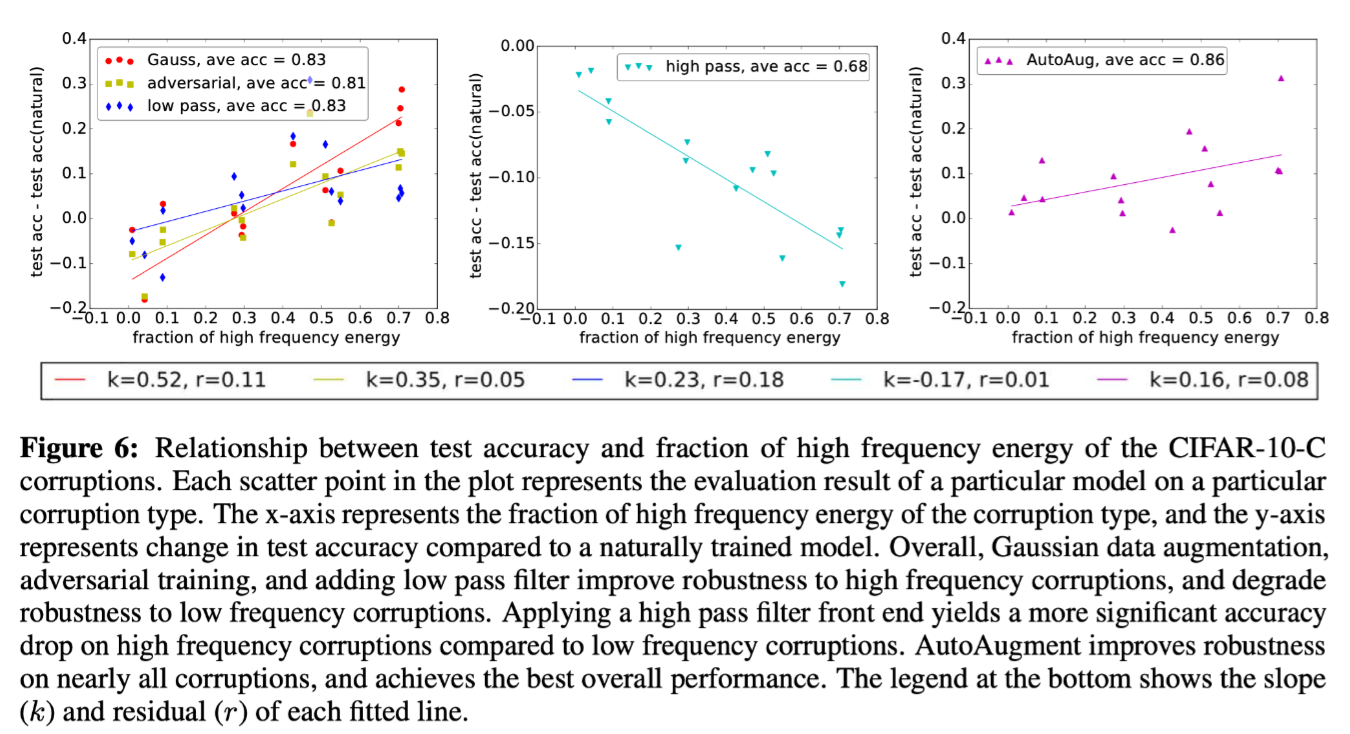
低频数据增强是否可以提高对低频损坏的鲁棒性?
通过上述的实验分析,自然引出这一问题。作者尝试应用与频域雾化扰动的统计数据相匹配的加性噪声,以测试低频数据增强能否提高模型对低频损坏的鲁棒性。将“雾噪声”定义为加性噪声分布 $\sum_{i,j} \mathcal N(0, \sigma^2_{i,j})U_{i,j}$,其中选择 $\sigma_{i,j}$ 以匹配基向量 $U_{i,j} $上雾化的典型范数。下表为测试结果,结果表明雾噪声的数据增强会降低图像雾化损坏的性能。
作者假设,由于自然图像中高频和低频信息之间的不对称性,低频扰动的情况更加复杂。而且由于自然图像更多的集中在低频,模型很容易学会忽略高频信息。
更多样化的数据增强提供了更通用的鲁棒性
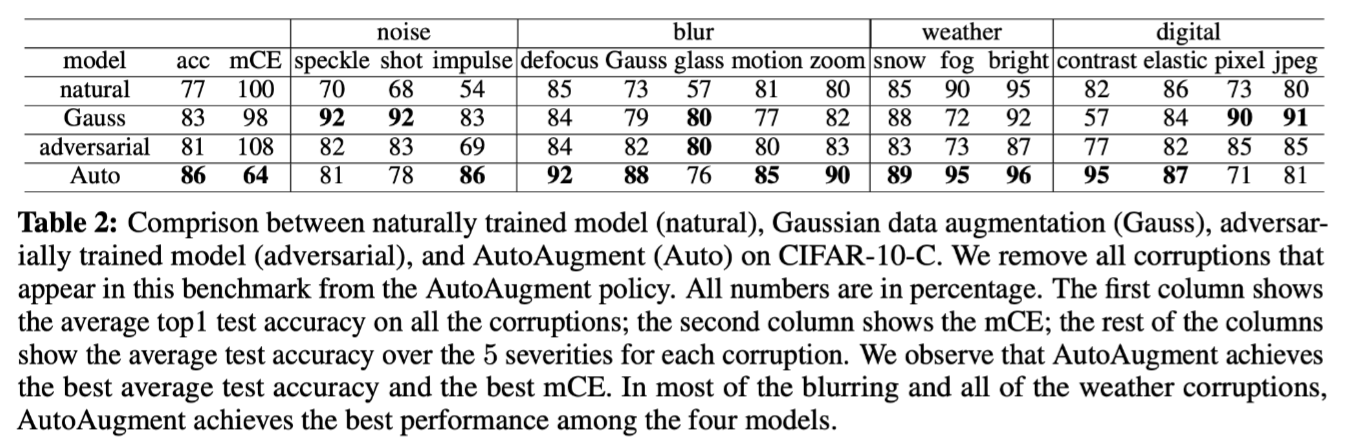
如何提高模型对更多样化扰动集的鲁棒性?一种直觉的方法是利用多种增强策略训练模型。作者采用AutoAugment,一种通过学习获得增强参数的自动增强方法,进行模型的评估。下表为不同增强方法在CIFAR-10-C上的评估结果,能够看到AutoAugment平均扰动测试准确率为86%,几乎提升了所有扰动的鲁棒性。
Adversarial examples are not strictly a high frequency phenomenon
当前针对对抗训练模型的一个常见的假设是对抗扰动主要位于高频域。作者采用 PGD (Projected Gradient Descent,基于梯度的攻击,来自论文 Towards Deep Learning Models Resistant to Adversarial Attacks) 为测试集中的图像构建对抗性扰动,之后分析自然图像与扰动图像之间的差值,并将这些差值投影到傅里叶域中。通过聚合成功的攻击图像,可以了解构建的对抗性扰动的频率特性,结果如下图所示。
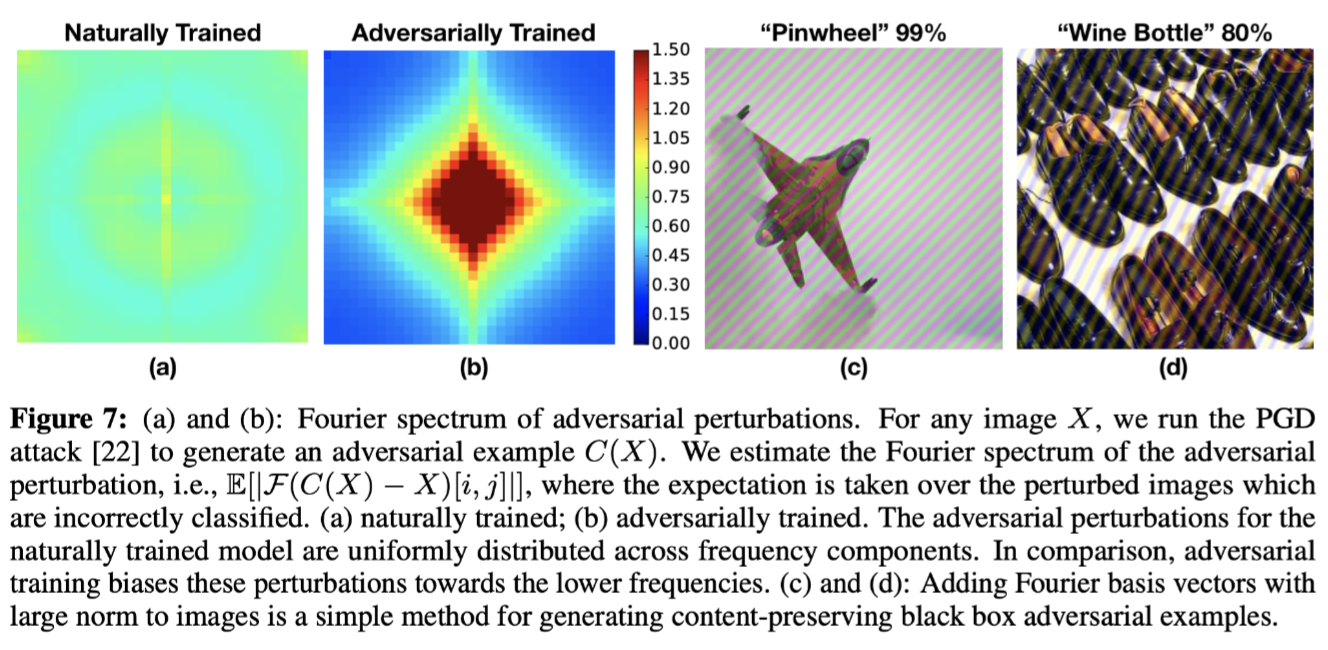
对于自然训练的模型,相当于自然图像的统计数据,对抗性扰动确实在高频域中表现出更高的浓度。然而,经过对抗训练的模型则不是这种情况。对抗训练模型的增量类似于自然数据的增量。首先,虽然自然训练模型的对抗性扰动确实在高频域中表现出更高的浓度,但这并不意味着从输入中去除高频信息会产生一个健壮的模型。如同上面的实验结论,自然训练的模型在任何频率上均没有表现出最坏的情况(除了极低频率)。这也解释了,如果在低频域中进行增强,不会得到较好的鲁棒结果。其次,对抗训练的扰动更加偏向较低频率。最后,作者观察到添加某些具有大范数的傅里叶基向量会在保留语义的同时将测试准确度降低到10%以下,扰动图像如下图右边两幅子图所示,这些傅里叶基向量可被视为一种黑盒攻击的方法。
Conclusion
本文利用傅里叶谱,建立起扰动频率与模型性能之间的联系。这种联系对于高频扰动最强,高斯数据增强和对抗训练使模型偏向于更依赖输入中的低频信息,这导致了提高了高频域中扰动的鲁棒性,代价是降低了对低频扰动和原始测试错误的鲁棒性。
基于实验数据,仅通过数据增强来提升鲁棒性是极具挑战的,如果只是单纯的增加不同的扰动类型通常不会有较好的结果。本文通过实验证明了 AutoAugment 在正确添加数据增强后能够较好的提升模型鲁棒性。另外,在利用数据增强时,需结合数据集以及实际情况合理添加,以免模型过拟合。训练模型的目的是学习域不变特征,而不是简单的对一组特定的扰动鲁棒。
同时文章的傅立叶分析表明,AutoAugment 模型的并不比基线更严格稳健——有些频率的稳健性降低而不是提高。因此,我们预计,稳健性基准将需要随着时间的推移和进展而演变。这些权衡是可以预料的,研究人员应该积极寻找他们引入的方法所导致的新盲点。随着我们对这些权衡的理解不断加深,我们可以设计更好的基准,以获得关于模型稳健性的更全面的观点。
虽然数据增强可能是目前解决稳健性问题最有效的方法,但单靠数据增强似乎不太可能提供完整的解决方案。为此,重要的是开发正交方法——例如,具有更好的归纳偏差或损失函数的架构,当与数据增强相结合时,鼓励外推而不是插值。
这篇文章拖了两个周终于读完了,获益匪浅,作者的思路清晰,实验详尽。从一个全新的视角来审视数据增强为模型带来的稳健性。

