Original Paper Reference:Text AutoAugment: Learning Compositional Augmentation Policy for Text Classification (Ren et al., EMNLP 2021)
这篇文章显然借鉴了图像领域的 Randaugment 论文 的思想,针对数据集和特定任务的数据增强策略寻找。
Introduction
现有的 NLP 数据增强方法主要分为两类:基于生成的和基于编辑的方法。
基于生成的方法使用条件生成模型从原始文本中合成新的近似文本,which have advantages in instance fluency and label preservation but suffer from the heavy cost of model pre-training and decoding;
基于编辑的方法则 instead apply label-invariant sentence editing operations (swap, delete, etc.) on the raw instance, which are simpler and more efficient in practice,即是通过在原始文本中使用一些编辑操作来生成新的样本。但缺点是 sensitive to the preset hyper-parameters including the type of the applied operations and the proportion of words to be edited.
作者在 IMDB 数据集的预实验说明了不同编辑操作和参数对于分类任务的影响是不同的,具体如下图所示。
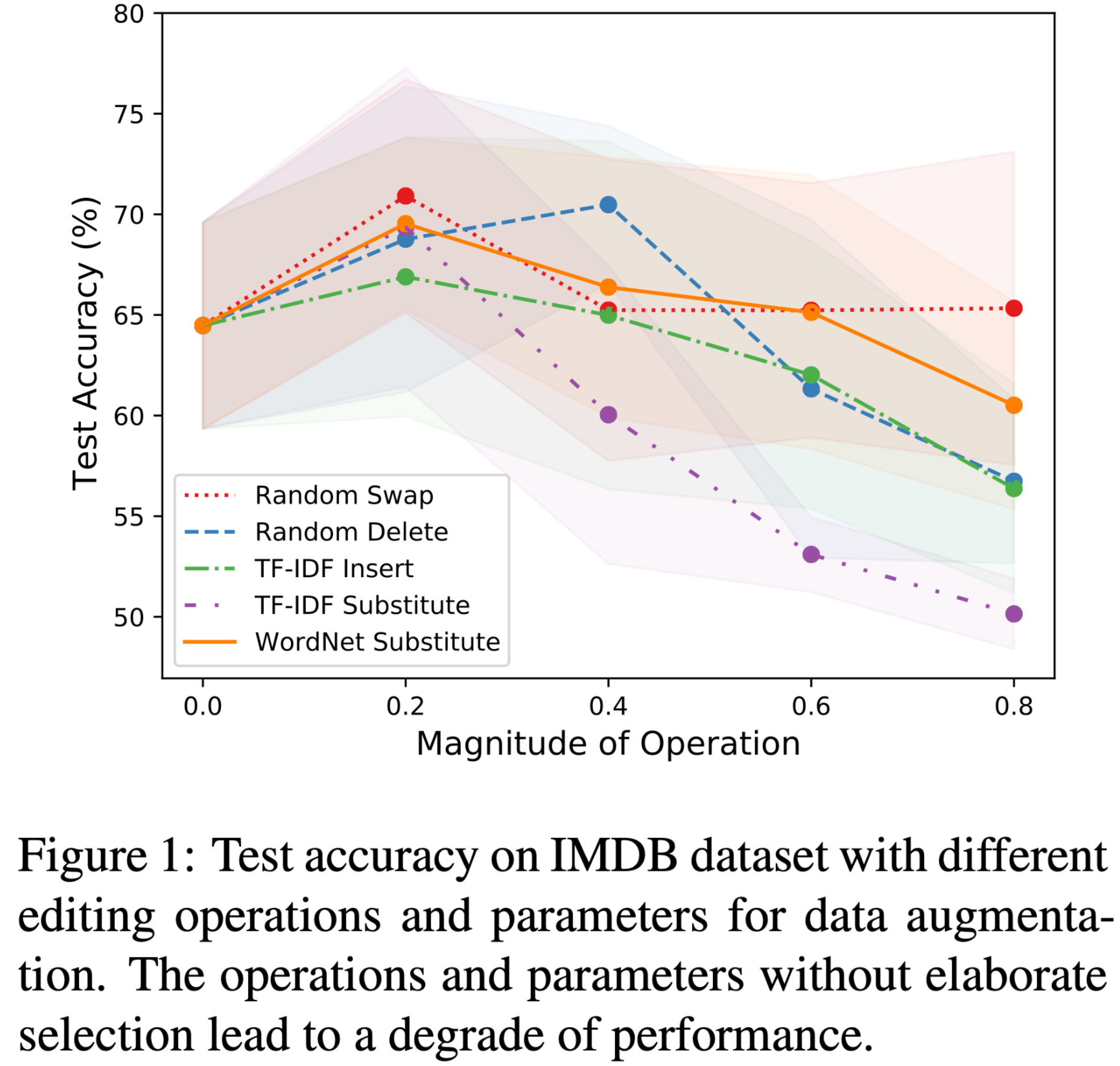
因此作者为了整合不同编辑操作,提出了 TAA 这个框架,目标是实现一个可学习的组合式的 DA 方法,其能生成一个更高质量的数据集从而提高文本分类任务模型的效果。具体的策略效果如图所示:
论文的总体贡献为两点:
We present a learnable and compositional framework for data augmentation. Our proposed algorithm automatically searches for the optimal compositional policy, which improves the diversity and quality of augmented samples
In low-resource and class-imbalanced regimes of six benchmark datasets, TAA significantly improves the generalization ability of deep neural networks like BERT and effectively boosts text classification performance
Text AutoAugment
形式化表述
组合式策略的描述如下:
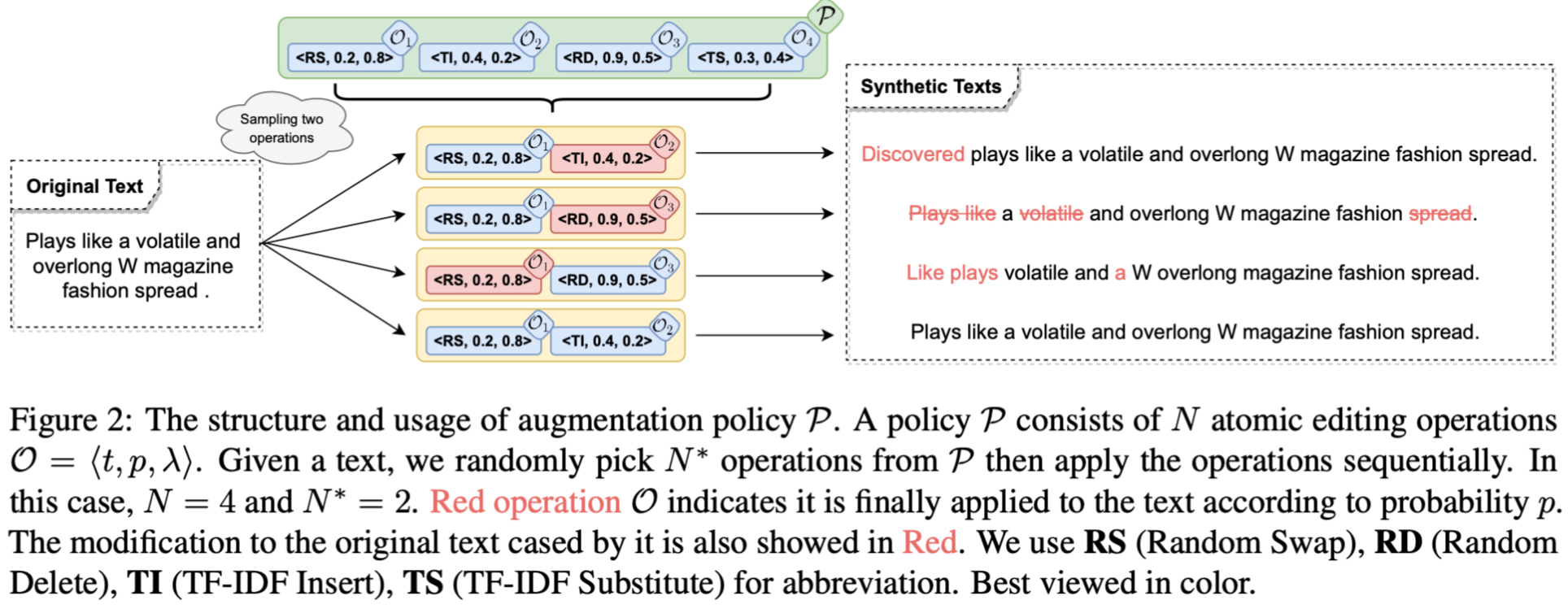
其中 The operation $\mathcal{O}$ is an atomic component and is responsible for applying an editing transformation on a text $x$ to synthesize an augmented instance $x_{aug}$. 每个编辑操作的形式化描述如下:
三个参数的意义:(1) Type $t \in$ {Random Swap, Random Delete, TF-IDF Insert, TF-IDF Substitute, WordNet Substitute}. 编辑操作的集合,五种操作。 (2) Probability $p \in [0, 1]$ of being applied, 即是操作对应的概率。 (3) Magnitude λ ∈ [0, 0.5] which determines the proportion of the words to be edited,即是句子被编辑的比例。
一个样本经过操作之后的结果形式化描述:
同时,该做操可以递归式进行,即是可以对一个样本同时或顺序施加多种增强操作。即是:
训练损失描述:Let $\mathcal{D}_{aug}(\mathcal{P})$ be the augmented dataset containing both training set and the synthetic data generated by the policy P, the loss function $\mathcal{L}$ of model training on the augmented dataset can be formulated as a sum of instance-level loss $\mathcal{l}$ such as cross-entropy.
作者将这一过程转化为 AutoML 中的 Combined Algorithm Selection and Hyper-parameter (CASH) 优化问题,具体描述:Formally, let $\mathbb{F}$ and $\mathcal{P}$ be the search space of models and policies, respectively. Each model $f$ is trained on $\mathcal{D}_{aug}(\mathcal{P})$ augmented by the policy $\mathcal{P}$. We propose a novel metric to measure the loss of a policy and a model:
这里式子右边的损失计算为:the loss that the model $f$ achieves on the validation set $\mathcal{D}_{val}$ after trained on the augmented set $\mathcal{D}_{aug}(\mathcal{P})$. It quantifies the generalization ability of the model after augmentation thus reflects the quality of the augmented data. Consequently, the objective function of our policy optimization can be written as:
但是这样的目标优化函数因为依赖于验证集损失,无法使用基于梯度的方法来优化,作者使用了 AutoML 中的贝叶斯优化方法:Sequential Model-based Global Optimization (SMBO),其优化过程如图所示:
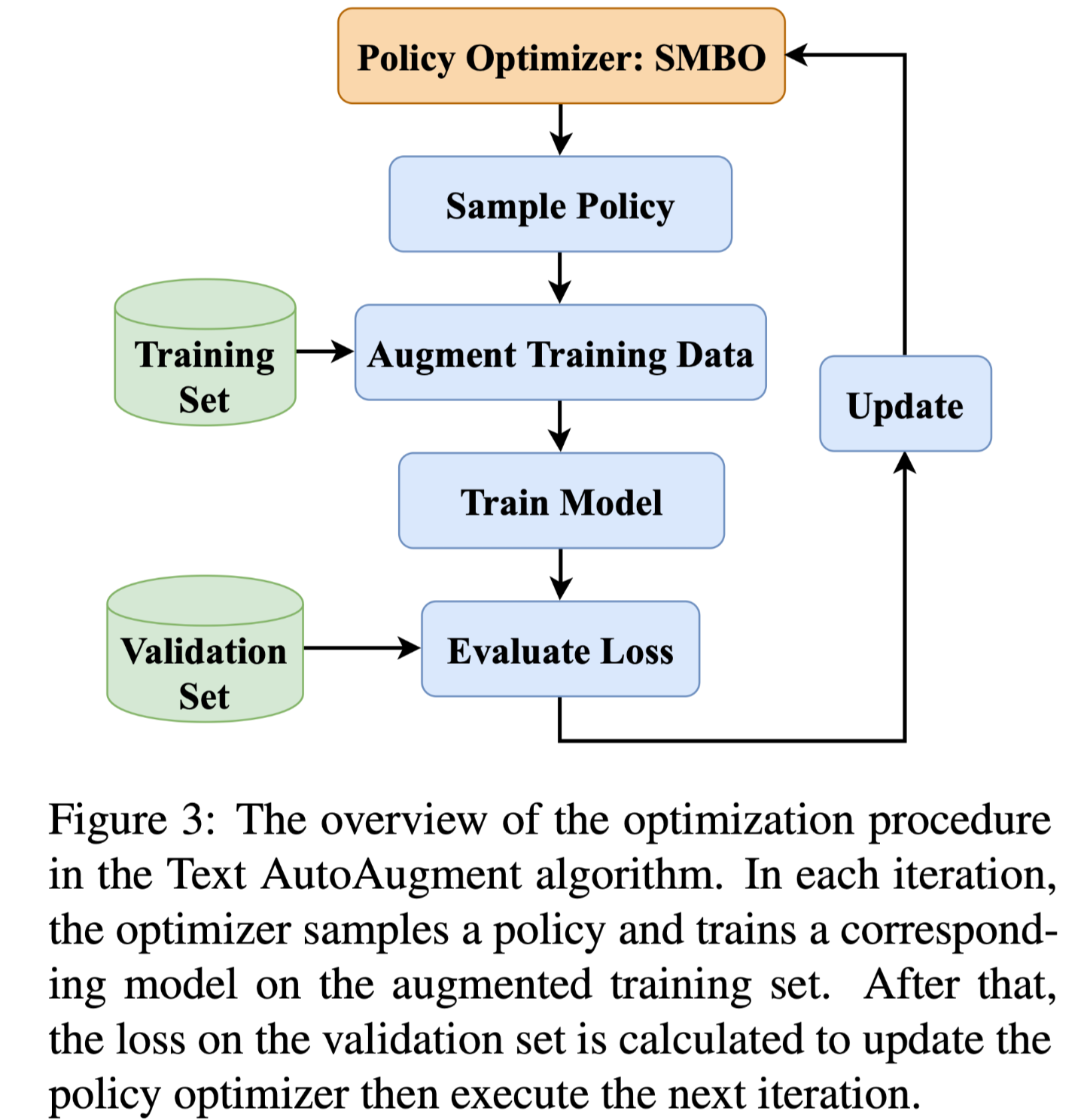
算法描述:

Experiments
数据集
使用的数据集有 IMDB (Maas et al., 2011), SST-2, SST5 (Socher et al., 2013), TREC (Li and Roth, 2002), YELP-2 and YELP-5 (Zhang et al., 2015) 六个。
对比的 baseline 有:
无增强模型
Back Translation (BT) 模型
Contextual Word Substitute (CWS) 模型
Easy Data Augmentation (EDA) 模型
Learning Data Manipulation (LDM) 模型
方法对比,作者提出的方法是兼顾了可学习和组合式的,基于字词层面的增强。

实验设置
作者在两种场景下进行实验验证,分别是低资源和类别不均衡。
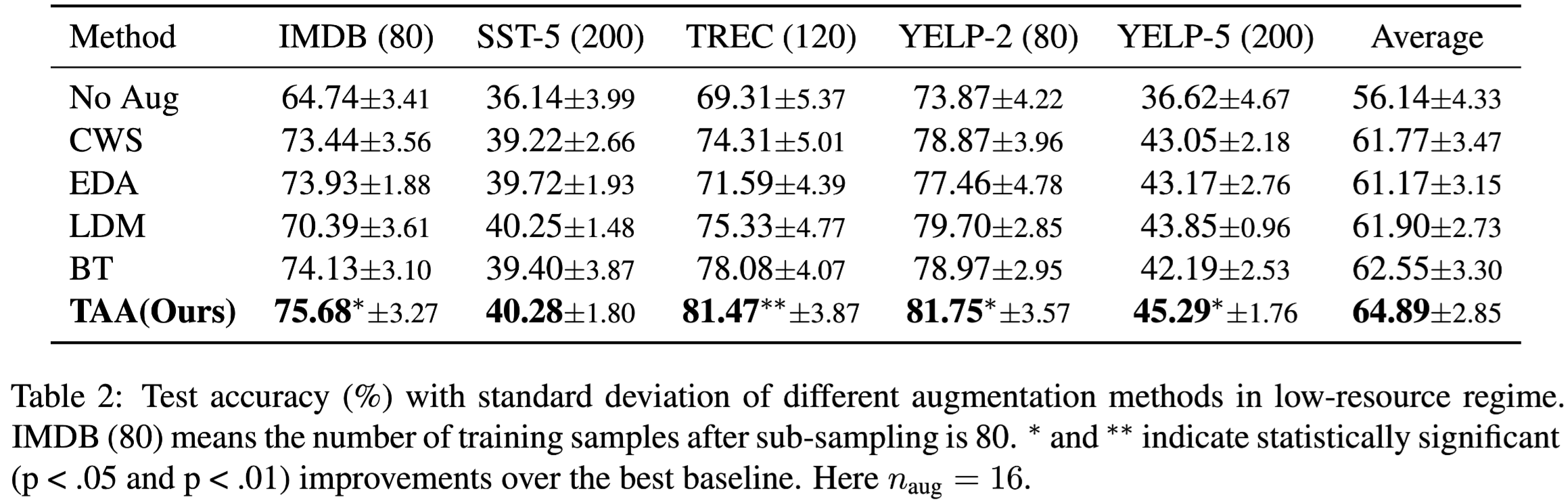
其中低资源限制场景下:apply Stratified ShuffleSplit (Esfahani and Dougherty, 2014) to split the training and validation set. The final datasets IMDB, SST-5, TREC, YELP-2, and YELP-5 have 80, 200, 120, 80, 200 labeled training samples, respectively, which pose significant challenges for learning a well-performing classifier. The number of validation samples is 60, 150, 60, 60, 150, respectively.In low-resource regime, we introduce a parameter naug, representing the magnification of augmentation. For example, naug= 16 means that we synthesize 16 samples for each given sample.
在类别不均场景下,人为采样:After sub-sampling, the negative class of the training set has 1000 samples, while the positive class has only 20/50/100 training samples respectively in three experiments,在增强方面,only augment the samples in positive class by 50/20/10 times, 使得增强后的数据集均衡。同时在为了对比,增加了一个 Over-Sampling (OS) 的 baseline,过采样的倍数也是一致的。需要说明的是,验证集的类别是均衡的。
在上述两种场景下,最终的测试集的数据均是均衡和完整的,这使得最终的测试结果是可信的。实验选取三个随机种子,每个实验五次,最终实验结果如下:
类别不均衡的实验结果:
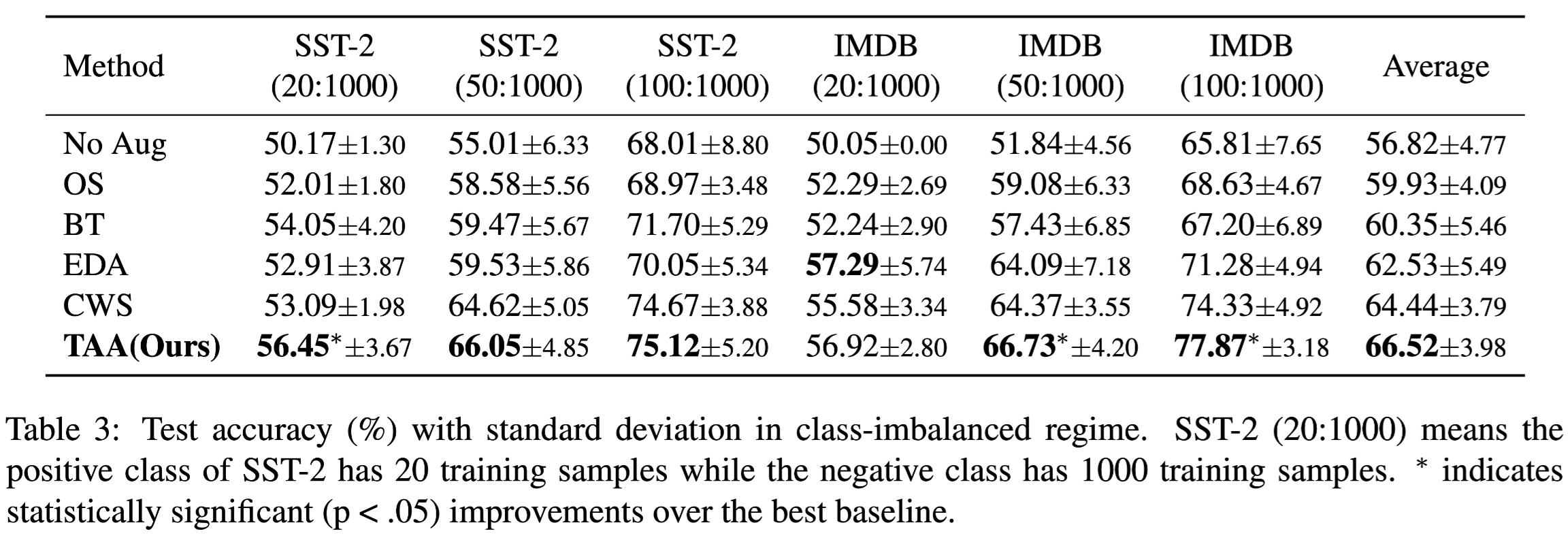
分析
策略迁移性
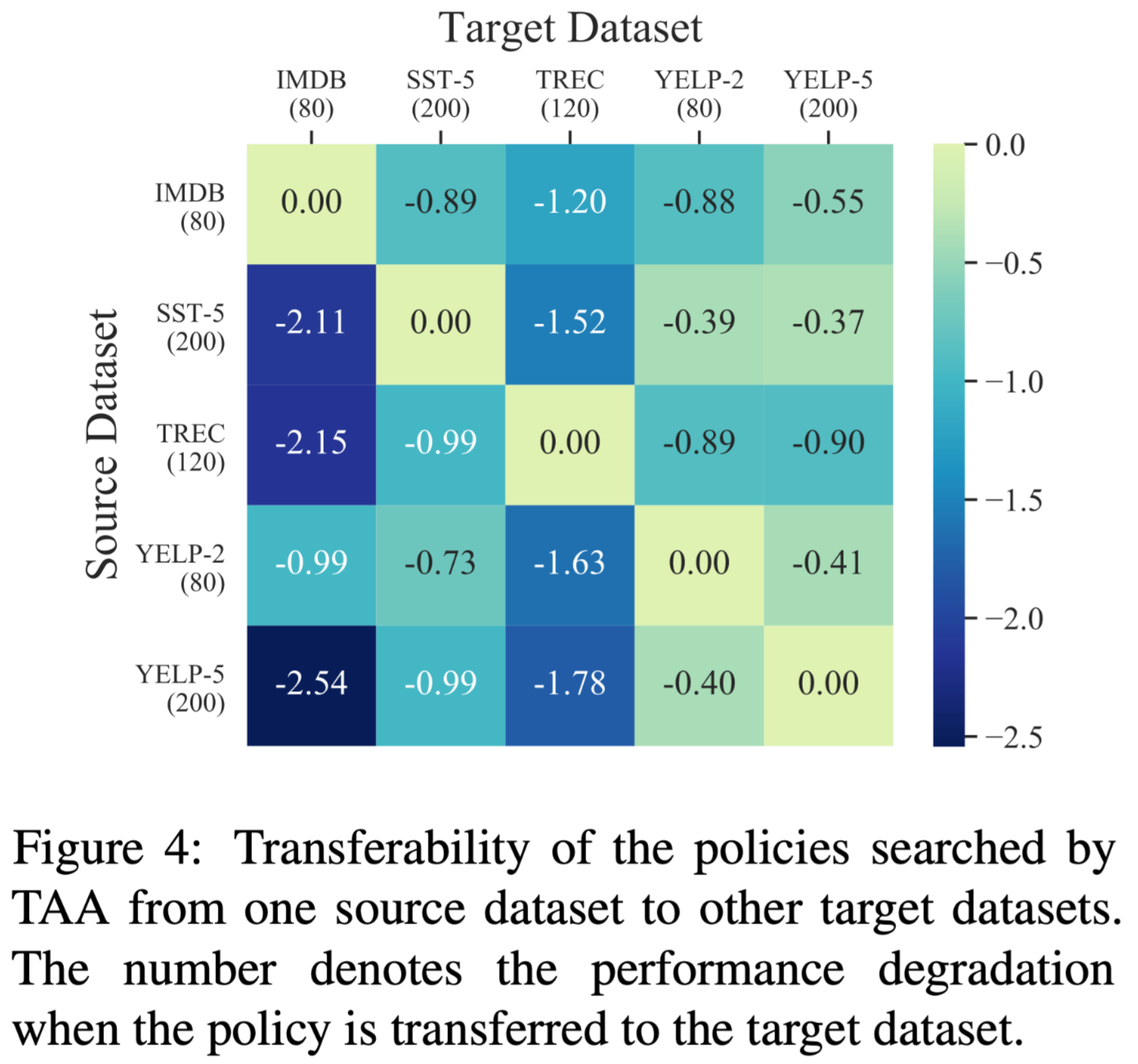
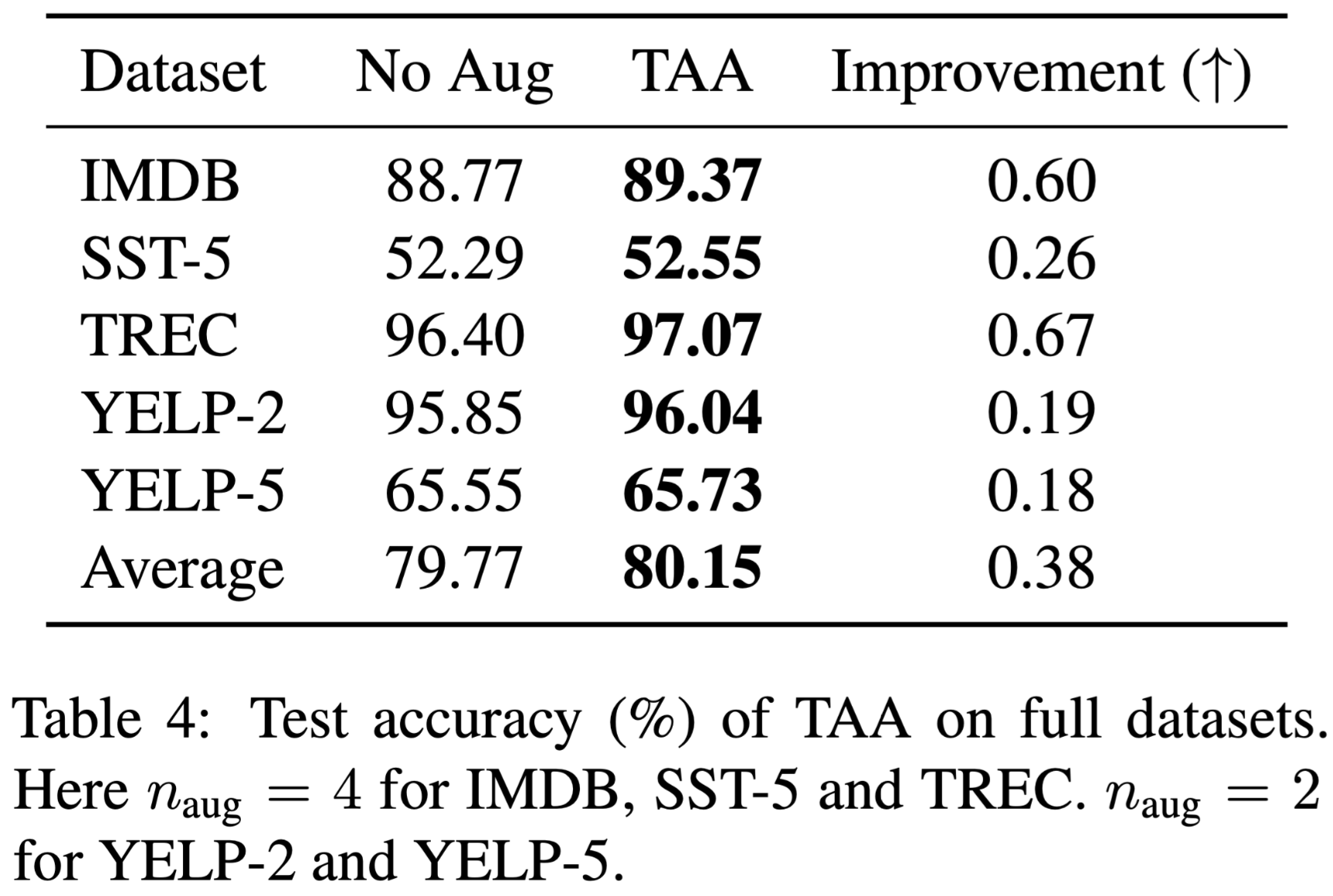
扩展性
将在低资源场景下学习到的增强策略(此时的训练样本为 2000 个,而非上述实验的样本数)应用于完整的数据集,最终结果:
增强强度倍数的影响
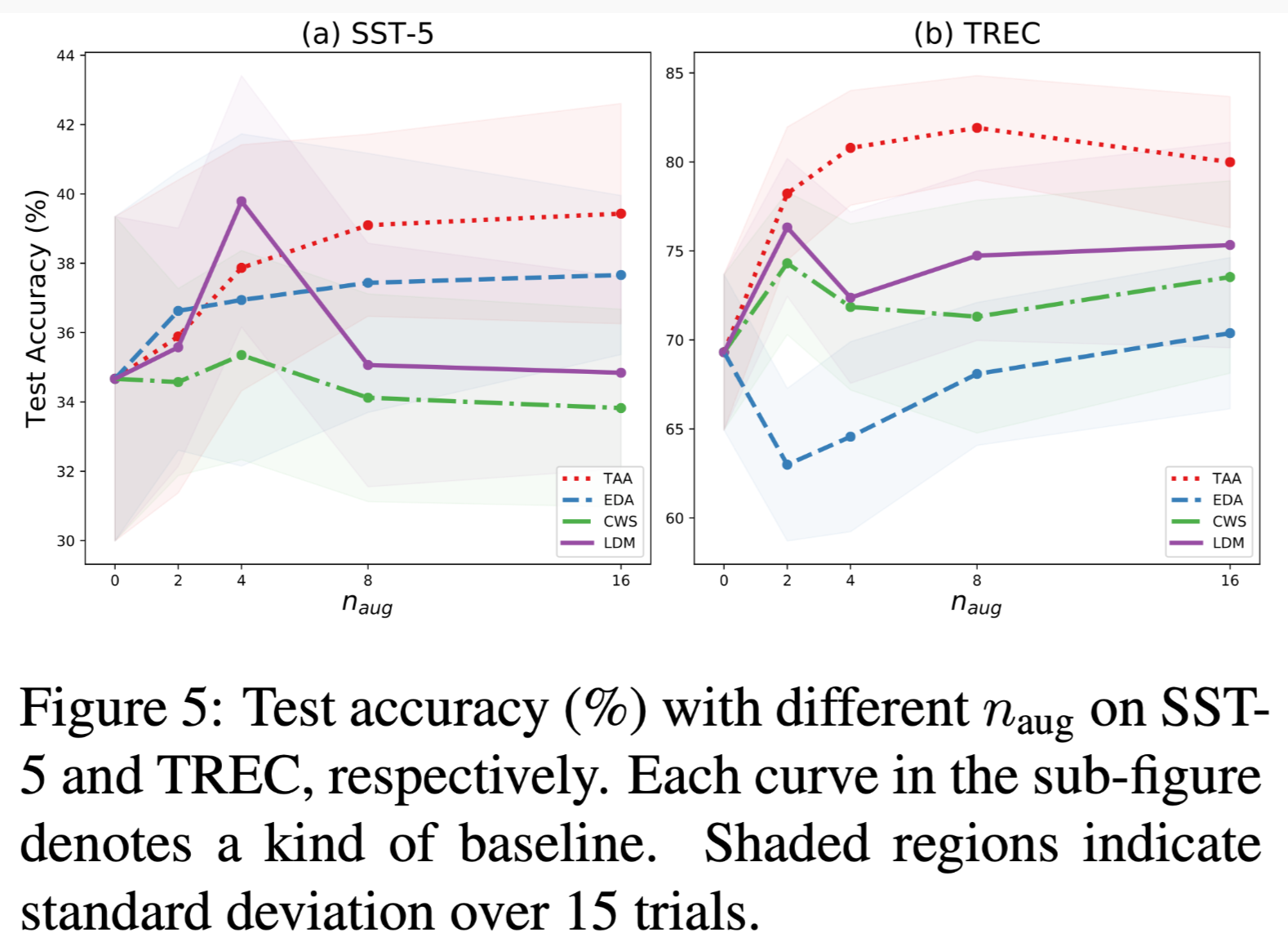
此处说明作者提出的方法可以有较为稳定的增强效果。
增强策略结构的影响
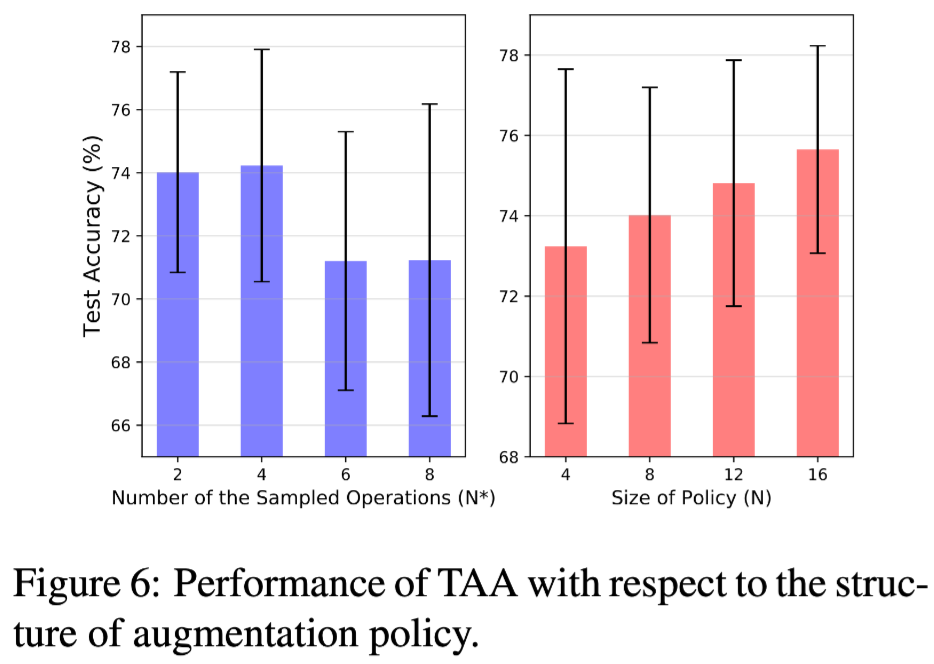
结论:左边的图说明 as $N^∗$increases, the original text is likely to be applied with more operations sequentially, which causes slight damage to the performance of TAA. While the right panel shows that the more operations a policy contains, the better TAA performs.
增强数据的多样性
We evaluate the diversity of the augmented data by computing the Dist-2 (Li et al., 2016), which measures the number of distinct bi-grams in generated sentences. The metric is scaled using the total number of bi-grams in the generated sentence, which ranges from 0 to 1 where a larger value indicates higher diversity.
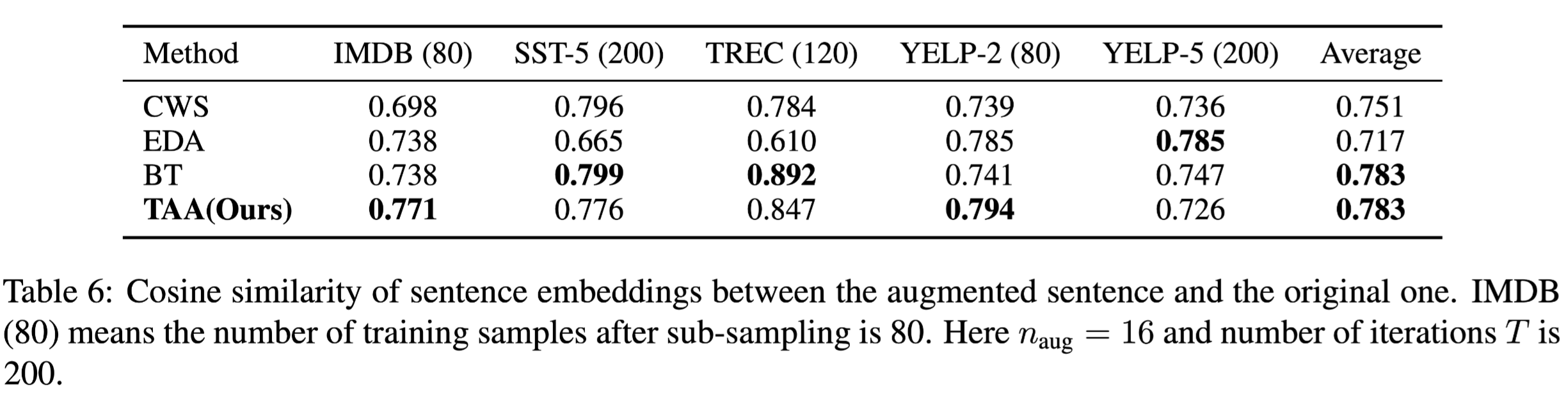
增强数据的语义保留性
使用指标为句子嵌入向量的余弦相似度,具体描述为:for the sentence pair $(x, x_{aug})$ consists of the original sentence $x$ and the corresponding augmented text $x_{aug}$, we utilize Sentence-BERT (Reimers and Gurevych, 2019) library, which achieves the state-of-the-art performance on various semantic textual similarity benchmarks, to obtain dense vector representations of sentences $(\bf{x}, \bf{x_{aug}})$ . The semantic preservation score $SP(x, x_{aug})$ is defined as:
Case Study

以上。

