Original Paper : A survey on Image Data Augmentation for Deep Learning | Journal of Big Data | Full Text
Introduction
In order to save time for reading more paper and coding, the content of this blog post will be mainly quoted from the original paper.
首先 motivation 是:
To build useful Deep Learning models, the validation error must continue to decrease with the training error. Data Augmentation is a very powerful method of achieving this.
The augmented data will represent a more comprehensive set of possible data points, thus minimizing the distance between the training and validation set, as well as any future testing sets.
这句话的意思是DA是一种十分有效的达到上述目标的方法,上述目标其实是防止模型的overfitting的发生,但是防止 overfitting of the model 方法 not only DA,论文介绍了其他几种methods, 其目的在于:
Knowledge of these overfitting solutions will inform readers about other existing tools, thus framing the high-level context of Data Augmentation and Deep Learning.
The detail will be showed in the mindmap:
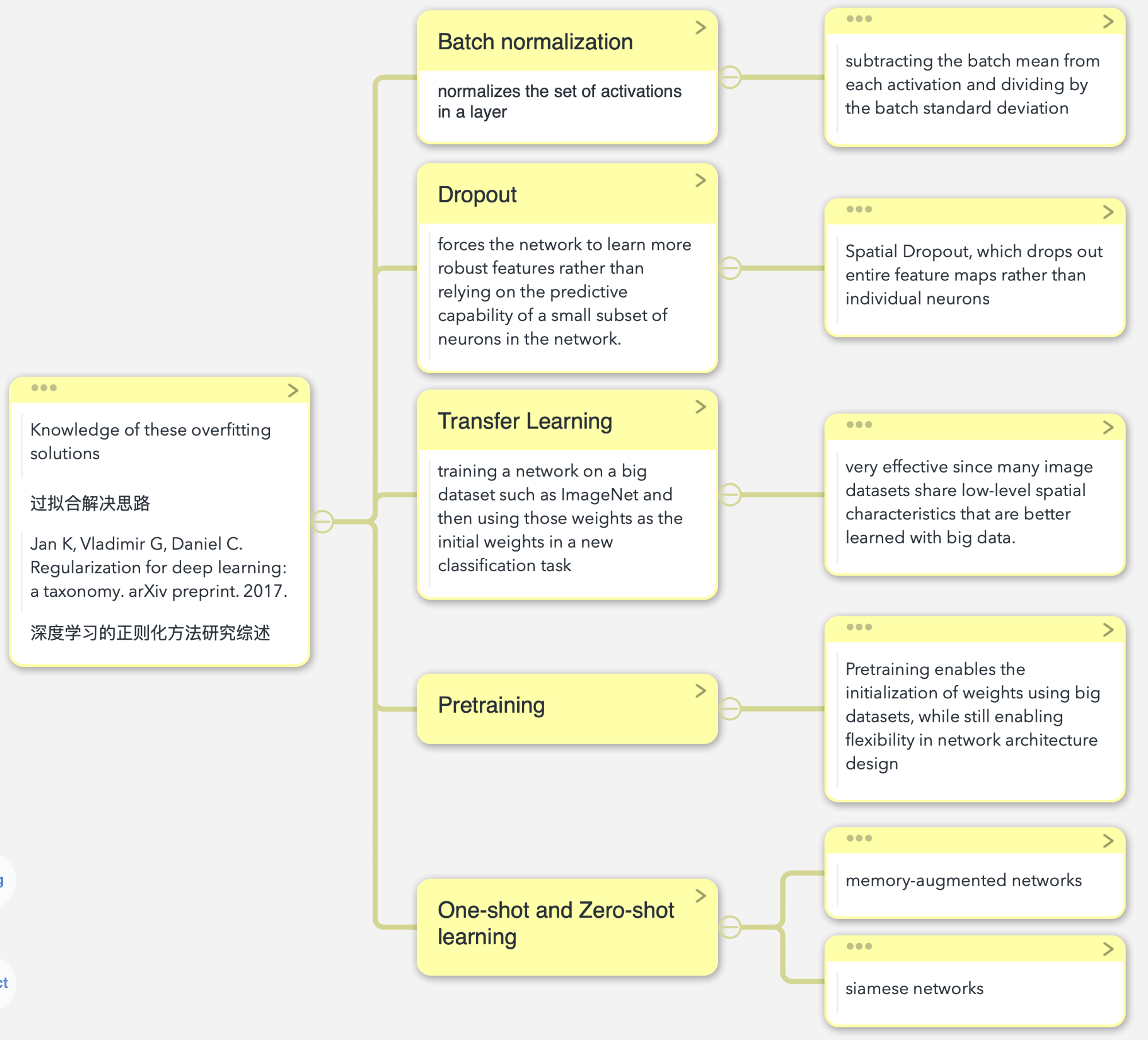
论文的行文立意在这一段话:
In contrast to the techniques mentioned above, Data Augmentation approaches overfitting from the root of the problem, the training dataset. This is done under the assumption that more information can be extracted from the original dataset through augmentations. These augmentations artificially inflate the training dataset size by either data warping or oversampling. Data warping augmentations transform existing images such that their label is preserved. This encompasses augmentations such as geometric and color transformations, random erasing, adversarial training, and neural style transfer. Oversampling augmentations create synthetic instances and add them to the training set. This includes mixing images, feature space augmentations, and generative adversarial networks (GANs). Oversampling and Data Warping augmentations do not form a mutually exclusive dichotomy.
即是DA是在训练数据层面进行数据的扩充训练模型,主要包括 Data warping or oversampling 这两种方式,并简单列举两种方式各自典型的方法。
论文对DA的主要框架总结:
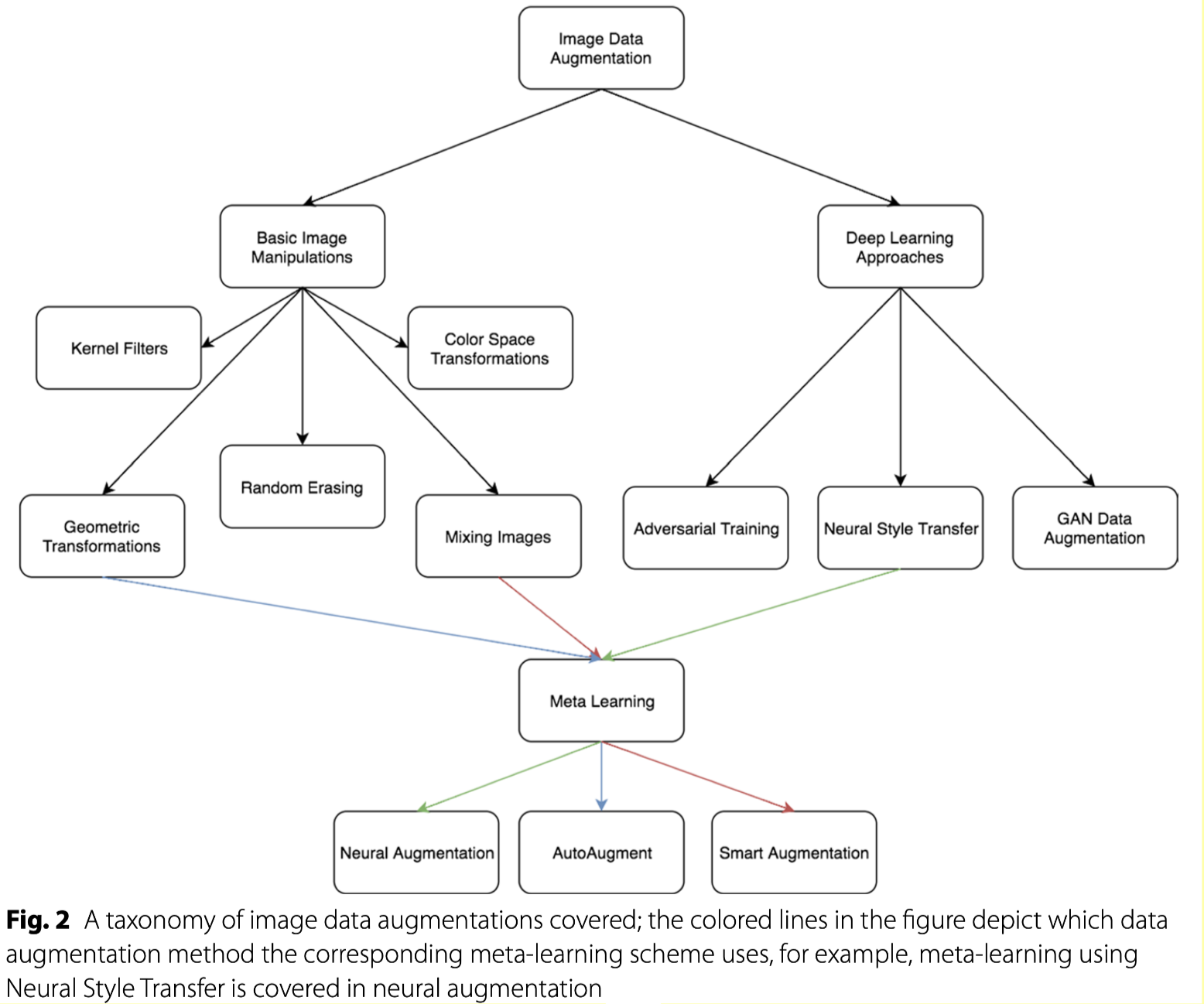
Image Data Augmentation techniques
主要是基于基础图像处理的数据增强,
Data Augmentations based on basic image manipulations
主要方式如下:
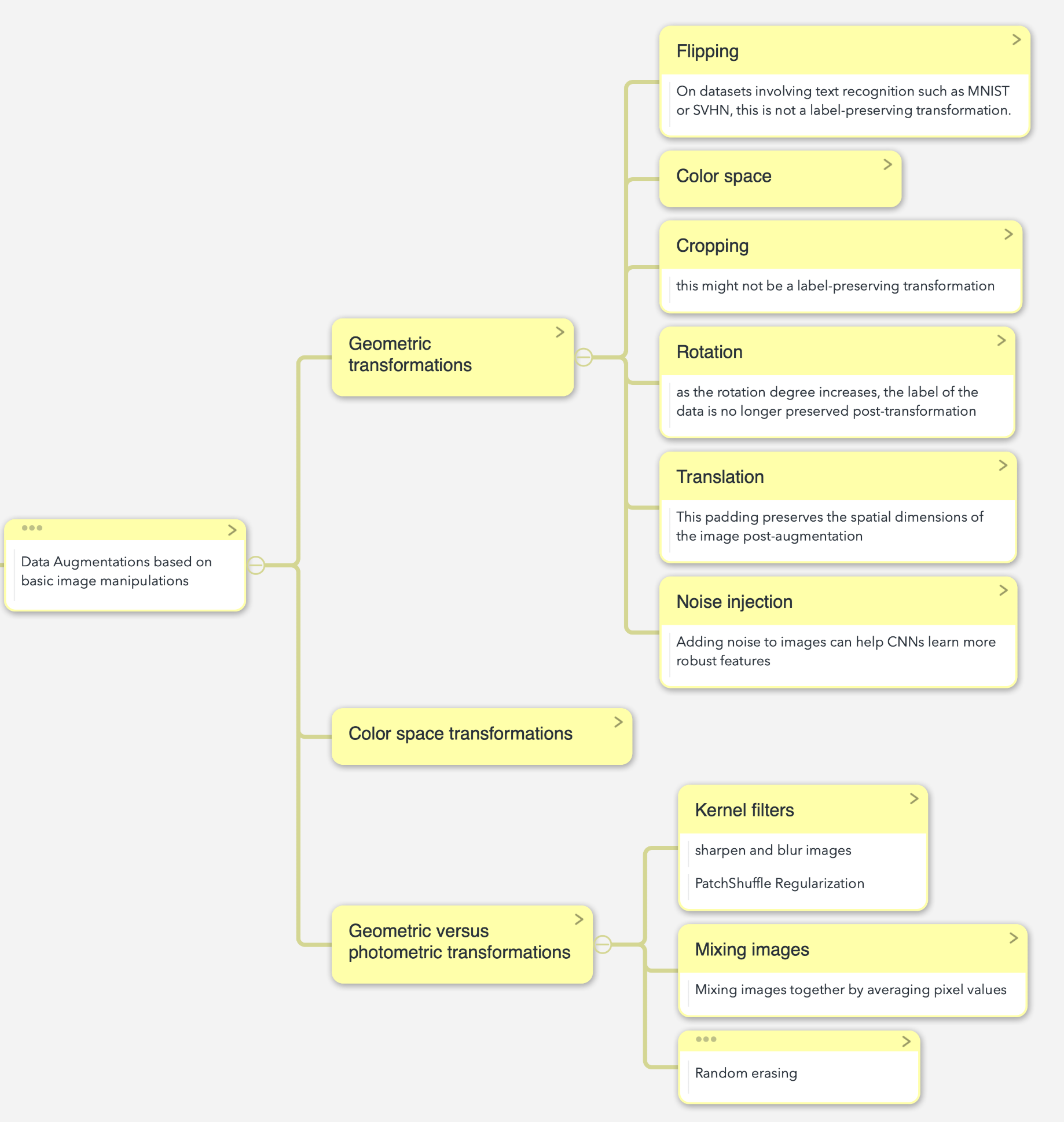
包括几何转换、颜色空间转换、几何及光度空间变换
Data Augmentations based on Deep Learning
基于深度学习的数据增强方法:
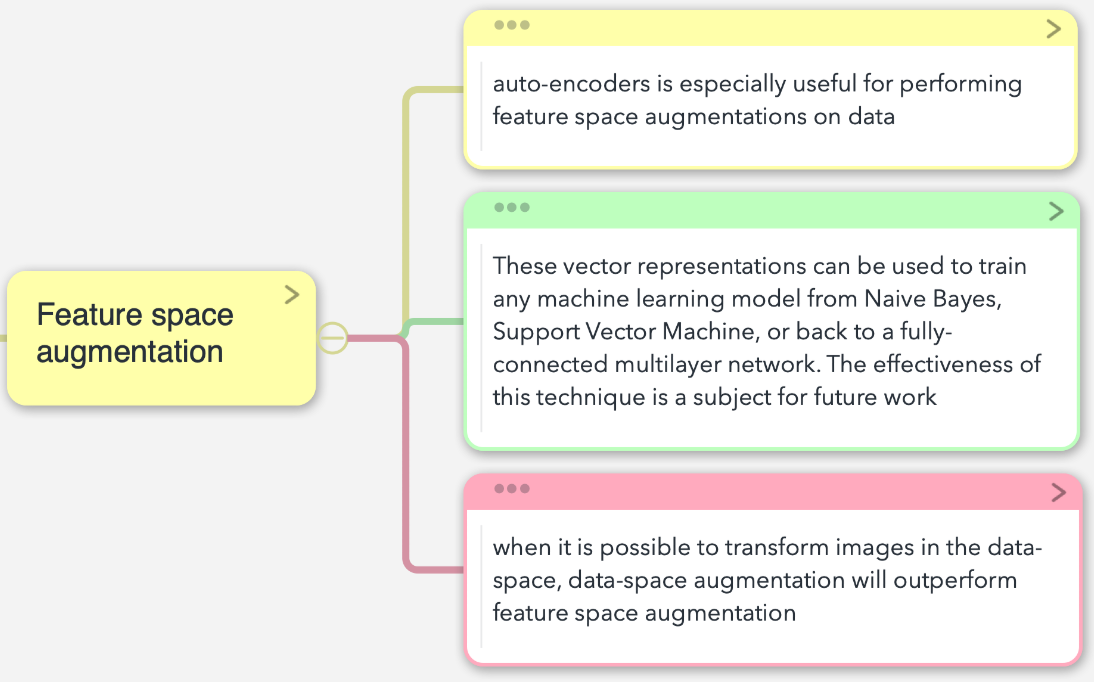
上述的数据增强方法都是在输入空间的,而特征空间(feature space)增强也被证明是非常有效的。
Feature space augmentation的研究方法框架
Adversarial Training的研究方法框架

GAN-based DA的研究方法框架

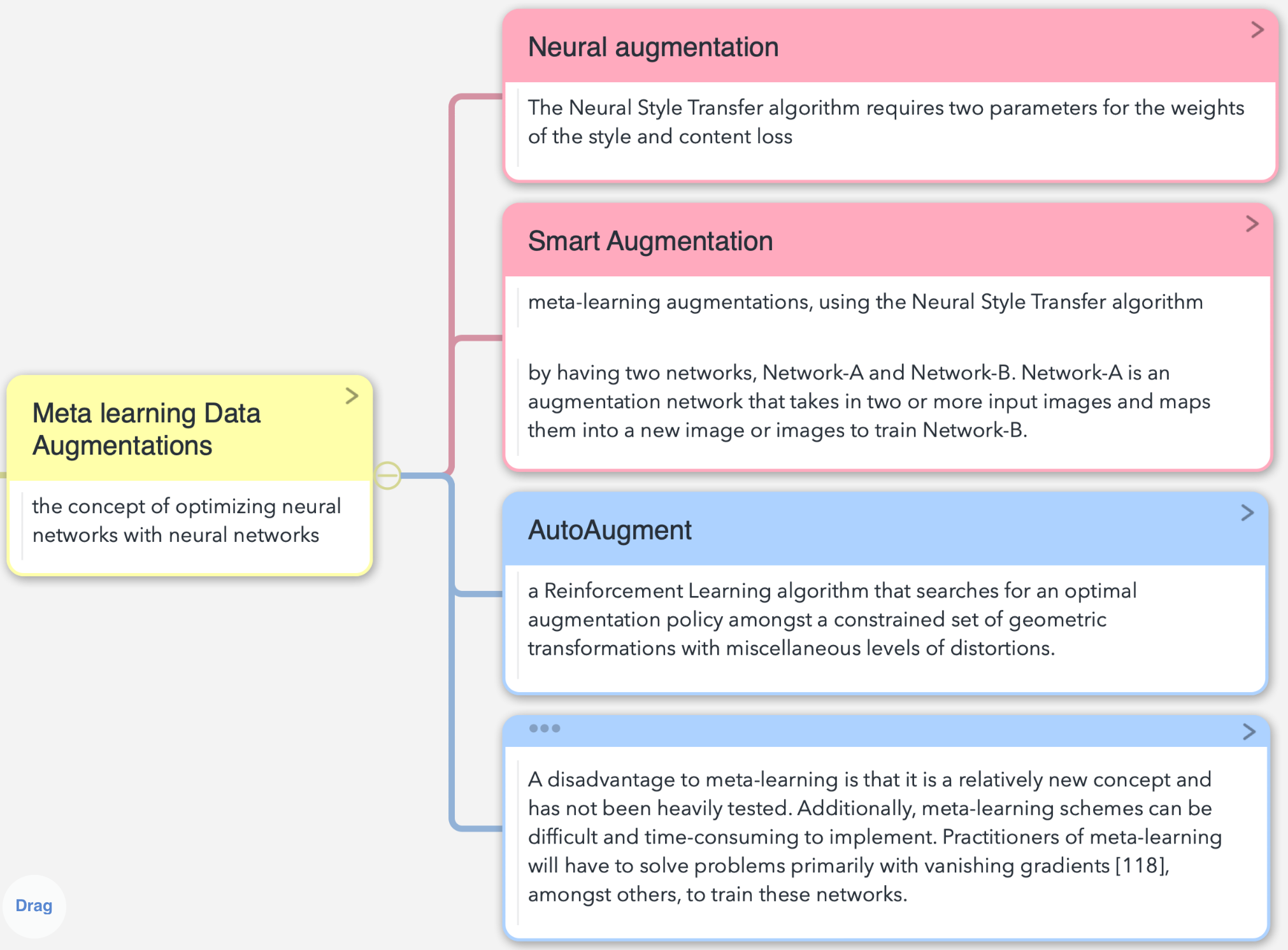
Meta learning DA的研究方法框架
Future work
总的来说建立DA技术的分类体系,目标是:
improving the quality of GAN samples, learning new ways to combine meta-learning and Data Augmentation, discovering relationships between Data Augmentation and classifier architecture, and extending these principles to other data types
同时针对神经网络结构本身:
The layered architecture of deep neural networks presents many opportunities for Data Augmentation. Most of the augmentations surveyed operate in the input layer. However, some are derived from hidden layer representations, and one method, DisturbLabel, is even manifested in the output layer. The space of intermediate representations and the label space are under-explored areas of Data Augmentation with interesting results. This survey focuses on applications for image data, although many of these techniques and concepts can be expanded to other data domains.
阅读总结
这是一篇 19 年的DA综述,里面按照第二幅图的框架总结了各种DA的方法和效果,并提出了未来一些潜在的研究方向。更多的19年以后的文章此文没有提及,读完之后会对DA有一个详细的发展脉络框架和技术体系方法的认识,尚值得细读一番。

