Original Paper Reference:A Survey of Data Augmentation Approaches for NLP (Feng et al., Findings 2021)
尽管在NLP领域的DA需求和热度不断增加,但是这一领域具体的DA研究依旧是相对较少,其原因或许是语言本身的离散特征。
这篇论文主要是针对当前NLP领域现有的一些DA研究进行综述,首先介绍了NLP领域DA相关的概念和Motivation,其次介绍了一些背景内容,第三点介绍了相关的技术和方法,之后则综述了相关的DA具体应用及相关任务下的DA应用,最后对NLP领域的DA面临的挑战和未来方向进行阐述。
Introduction
当前 NLP 领域 DA 研究稀缺的原因是:
perhaps due to challenges presented by the discrete nature of language, which rules out continuous noising and makes it more difficult to maintain invariance.
同时点出论文的目的:
(i) give a bird’s eye view of DA for NLP, and (ii) identify key challenges to effectively motivate and orient interest in this area.
Background
再次提到当前的DA大部分都是在现存数据上做微小修改或合成数据,目的是为了作为正则项和减少过拟合。
再次提到离散空间问题:
In NLP, where the input space is discrete, how to generate effective augmented examples that capture the desired invariances is less obvious.
DA 的目标:the distribution of augmented data should neither be too similar nor too different from the original
同时点出当前DA研究的一大问题是缺少研究 why exactly DA works?
Existing work on this topic is mainly surface-level, and rarely investigates the theoretical underpinnings and principles
Techniques & Methods
第一点是基于规则的技术,其次是样本插值技术,最后是基于模型的技术,具体如下:
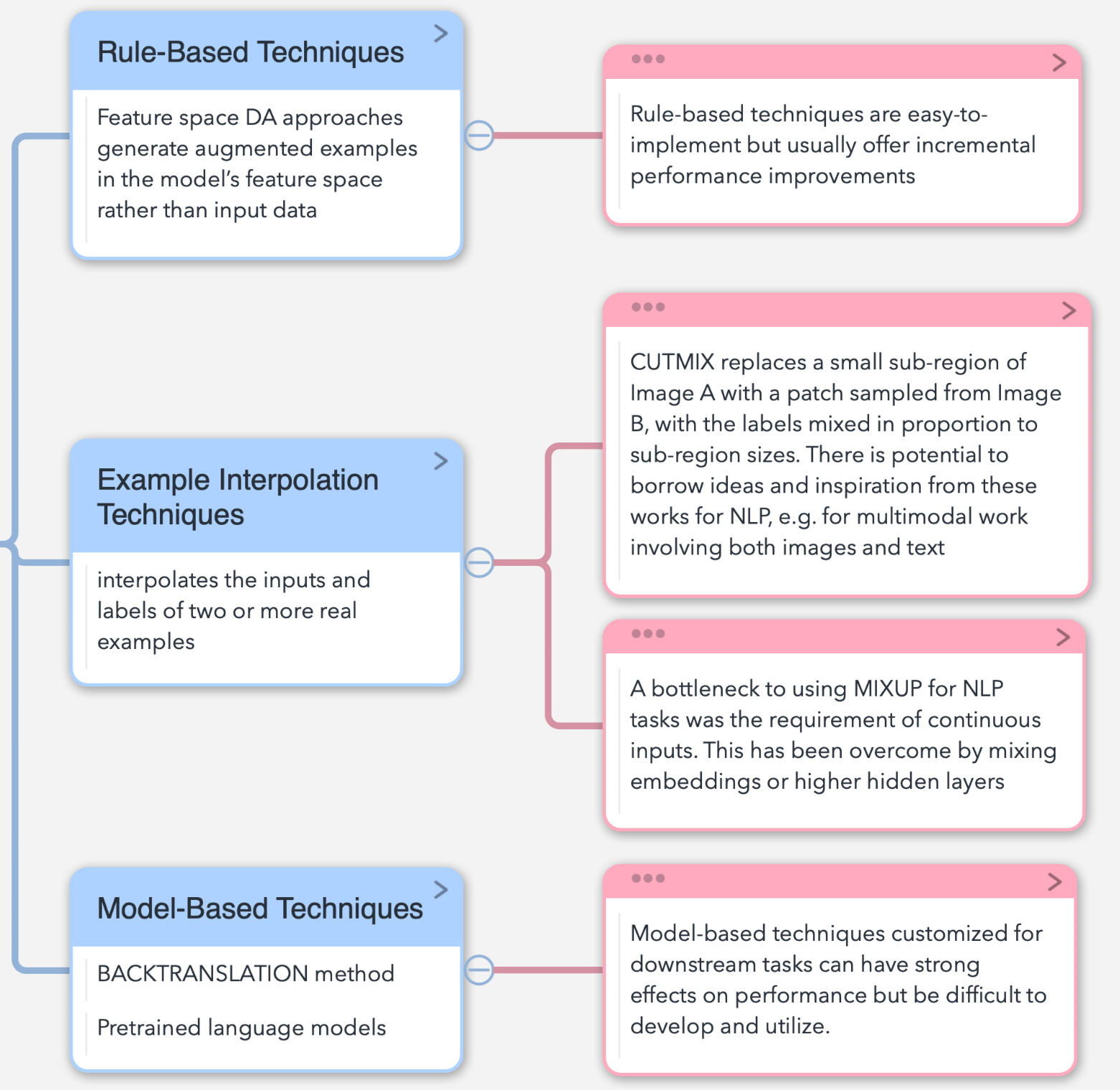
Applications
主要包括以下五大应用场景:
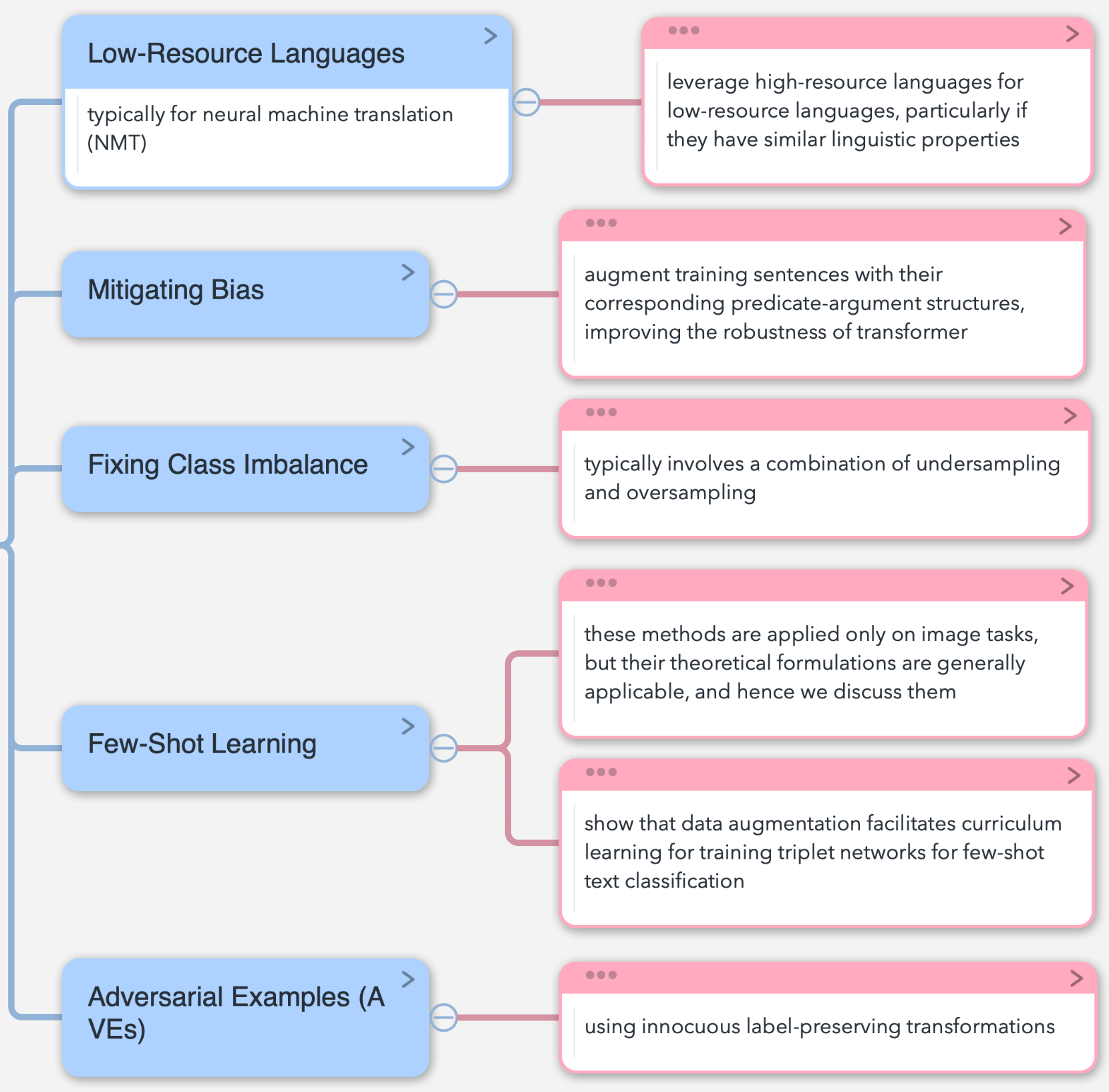
Tasks
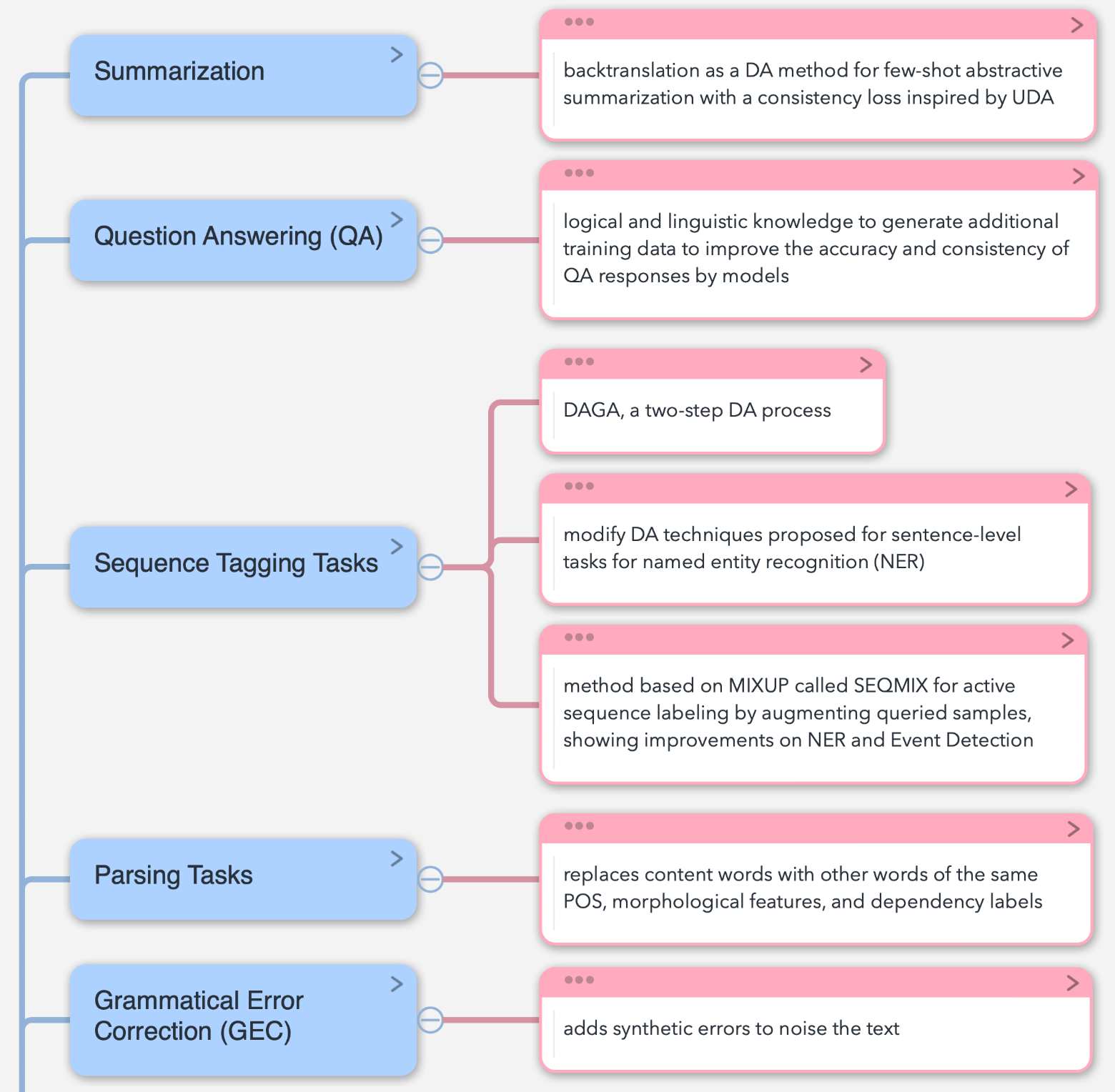
相关任务非常多,其中均有涉及到DA的应用,但是程度不一,且应用都处于起步阶段。
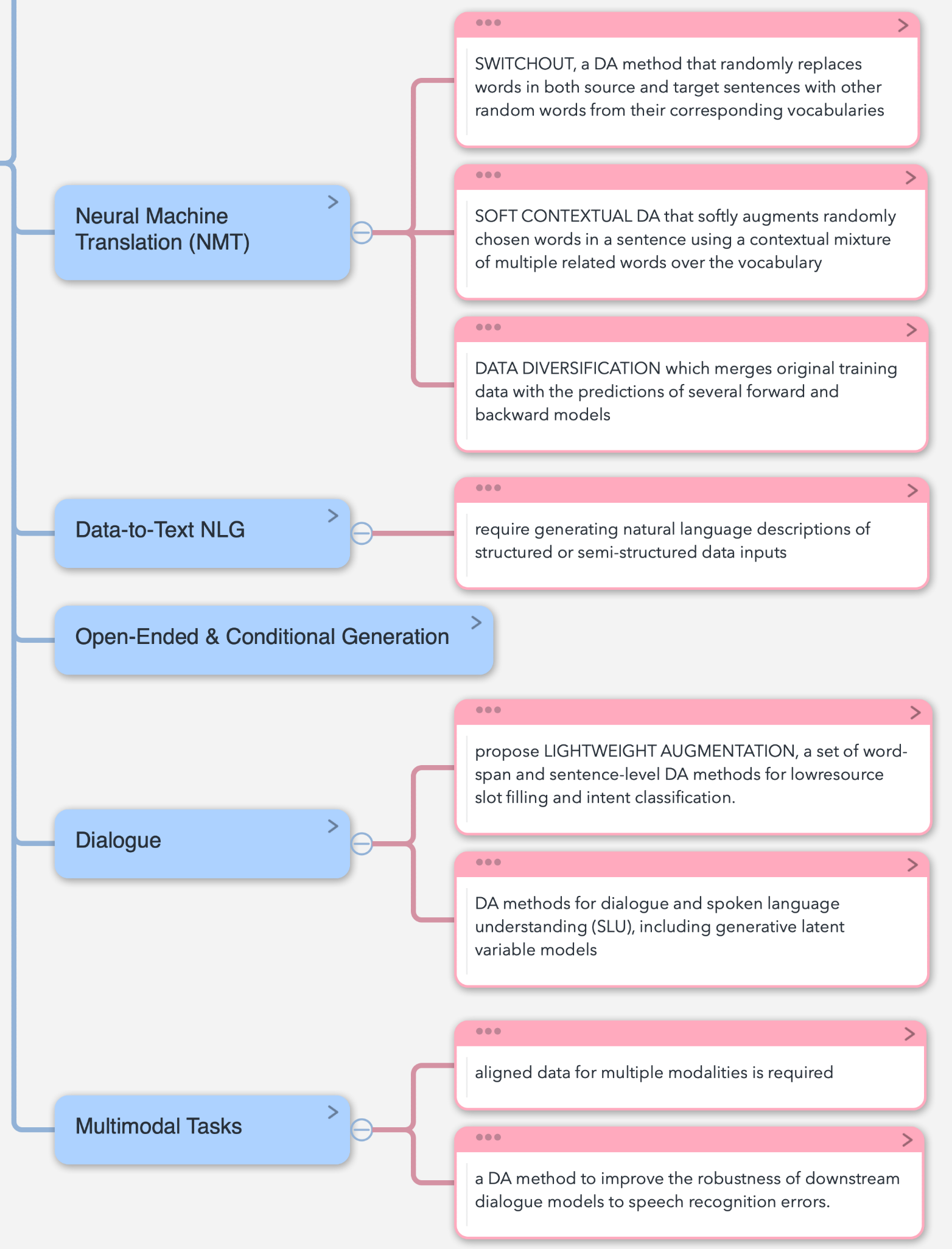
挑战及未来方向
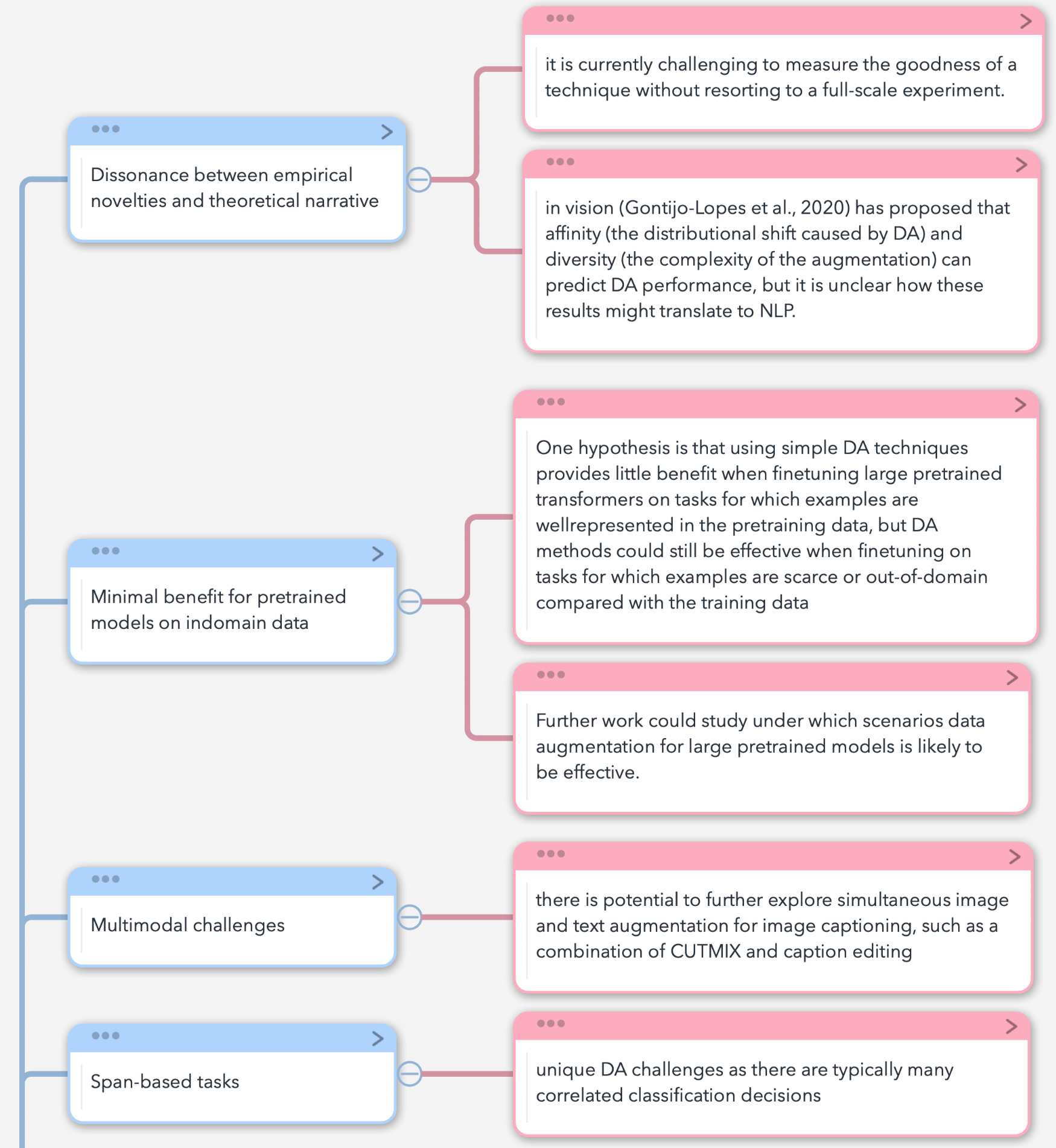
低一点是实证和理论之间的差距,如何预知和衡量DA的效果,如何解释DA的作用?第二点是在现有大规模预训练语言模型的基础上DA的作用微乎其微,在存在大型预训练语言模型的基础上哪些场景下DA会有效?
第三点是多模态的挑战,比如图像文本标注生成问题上。
第四点是基于span的任务中DA如何应用?
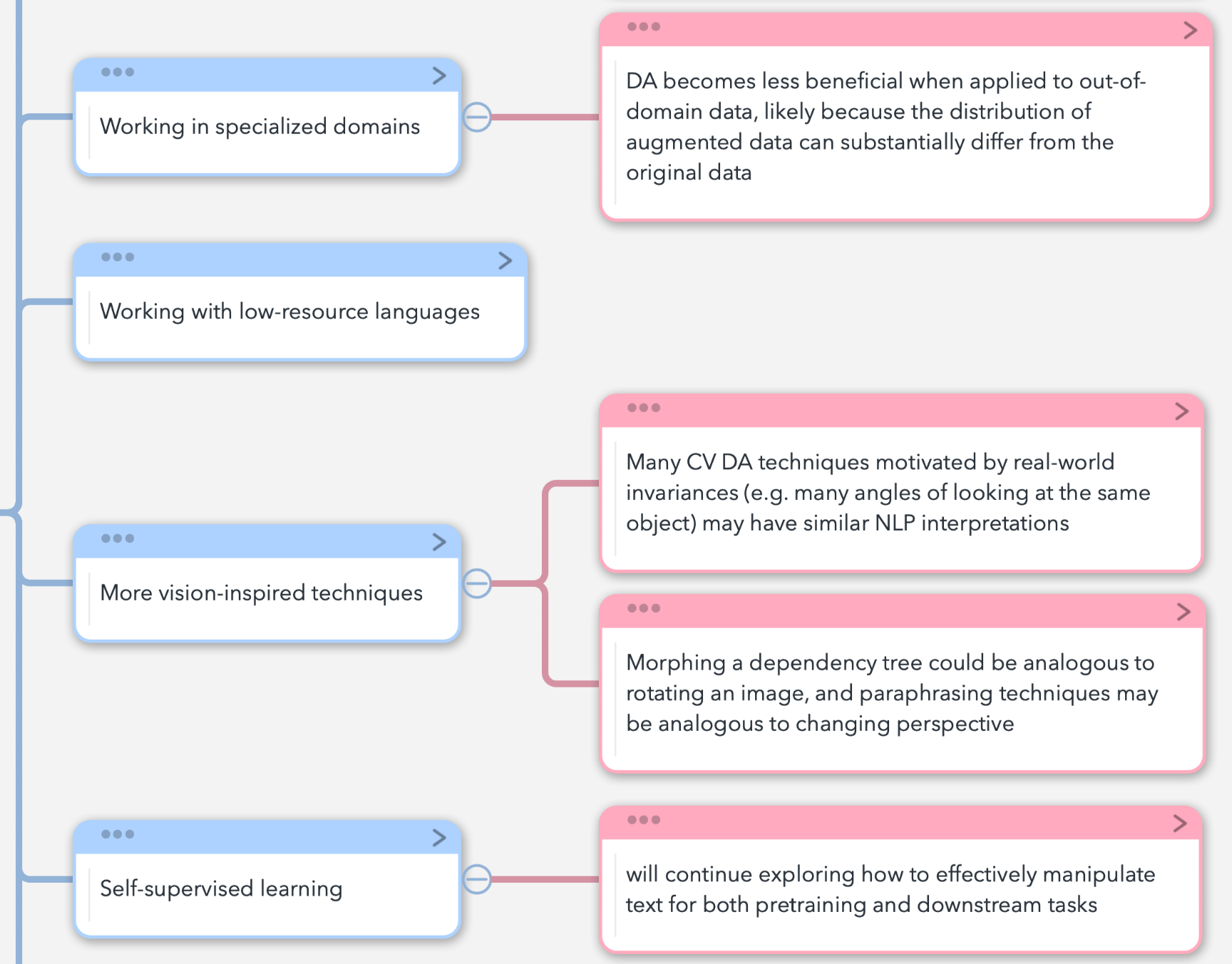
这里图里面很清楚了。

这里主要说的是当前 NLP 领域的 DA 研究离线可用的轻量级DA扩展模块,缺乏一个统一的框架,也缺乏公开的标准数据集,缺乏更深入的参数级别的研究,更不用说对 DA 背后的直觉和理论的讨论研究来提高 DA 的可解释性和透明性。
阅读总结
这是一篇21年的ACL的 NLP 数据增强综述文章,当前NLP领域中数据增强的方法都是处于探索阶段,没有清晰的发展脉络,思路也较为混乱。当前大多是都是从CV领域借鉴思想迁移到NLP领域,但是NLP领域本身的数据特性,导致CV中的方法并不能直接照搬,同时大规模与训练语言模型的存在使得DA的作用进一步受限,但我认为这里的受限更多是在嵌入表示层面的增强受限,在高维特征或者深层特征表示上,DA依然有用武之地,同时在特定领域、特定问题上也是如此。

