# 确定待分类实例的 k 近邻 deffind_labels(k,train_images,train_labels,test_image): all_dis = [] labels=collections.defaultdict(int) for i inrange(len(train_images)): dis = np.linalg.norm(train_images[i]-test_image) all_dis.append(dis) sorted_dis = np.argsort(all_dis) count = 0 while count < k: labels[train_labels[sorted_dis[count]]]+=1 count += 1 return labels
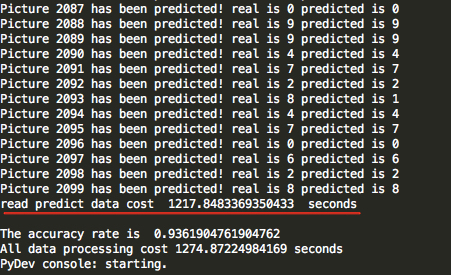
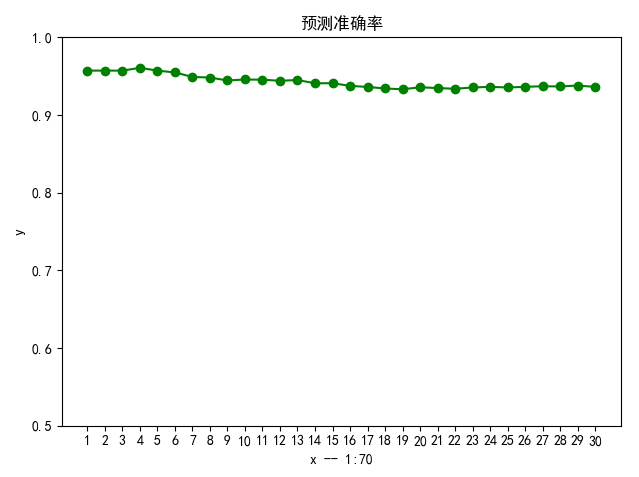
# 结合训练数据集,对所有待分类实例进行 k 近邻分类预测 defknn_all(k,train_images,train_labels,test_images, test_labels): print("start knn_all!") res=[] right = 0 accuracy = [] count=0 for i inrange(2100): labels=find_labels(k,train_images,train_labels,test_images[i]) res.append(max(labels)) print("Picture %d has been predicted! real is %d predicted is %d"%(count, test_labels[i], max(labels))) count+=1 ifmax(labels) == test_labels[i]: right+=1 if (i+1) % 70 == 0: accuracy.append(float(right)/(i+1)) return res, accuracy
# 总的预测准确率计算 defcalc_precision(res,test_labels): f_res_open=open("res.txt","a+") precision=0 for i inrange(len(res)): f_res_open.write("res:"+str(res[i])+"\n") f_res_open.write("test:"+str(test_labels[i])+"\n") if res[i]==test_labels[i]: precision+=1 return precision/len(res)
if __name__ == '__main__': print('Start process train data') time_0 = time.time() # tl.get_train_set()
print('Start process test data') time_t = time.time() # tl.get_test_set()