Introduction
传统的数据增强方法普遍需要专家知识来手动设计策略获取对应领域的先验知识,这导致增强方法的领域依赖性强,泛化能力不够。数据扩充的策略学习方法——自动设计扩充策略方法出现,有可能解决传统数据扩充方法的这些弱点。这种方法通过训练一个机器学习模型来学习一种数据增强策略,从而可能提高模型在半监督学习上的准确性、鲁棒性及表现。特别的,所有的这些提升不像改进网络结构的方式那样会在模型的推断阶段造成计算时间的消耗。
原始的数据增强方法有这样的一个范式:现在一个小型数据集上定义一个代理任务进行模型训练,可以理解为子数据集的进行子任务训练,然后将模型迁移到更大规模数据的目标任务上。这种范式得到的数据增强模型确实可以提高模型任务的表现,但是它依赖于一个很强的假设,即是这代理任务的模型性能与在迁移的更大数据集上目标任务上的性能相似。
然而文章作者通过实验验证了这一假设得到的模型并不是最优的,有可能是次优的结果。数据增强的力度和参数同数据集和模型的大小均有较强的关联关系。
由此,作者思考是否可以直接去除代理任务的参数搜索过程,直接进行目标任务的数据增强策略的构建。
但这就需要解决一个问题,就是较早期自动数据扩充方法(NAS)方法,需要单独的优化过程及大规模的参数搜索过程,大大增加了训练机器模型的计算成本和复杂性。如果去除代理任务的搜索过程,那么需要大大简化目标任务数据增强策略的参数搜索成本。
论文提出了一种实用的自动数据增强算法RandAugment。该方法无需在子任务上进行搜索验证。该方法仅有两个参数进行数据扩充,大大简化了参数搜索空间,直接使用简单的格点搜索(simple grid search)方法就可以获取到十分有效的数据增强策略。通过实验证明,该方法优于目前所有的采用单独的子任务搜索方法进行自动学习的数据增强方法。
Method
该方法的核心参数代码如下:
1 | import numpy as np |
一共选取了K=14种图像增强策略方法,N是每次需要选取的策略方法数,另一个参数 distortion magnitudes M是选择的策略的强度即形变程度。对于每种数据增强方式的选择可能性均相等,因此潜在的训练策略就包含 $K^N$种,每种增强方法都被放缩到整数0到10之间,10代表最大增强变换程度。
在训练期间,作者用四种方法对增强强度 M 的变化进度进行了实验:恒定幅度、随机幅度、线性增加幅度和增加上限的随机幅度。
验证代理搜索任务的最优假设缺陷
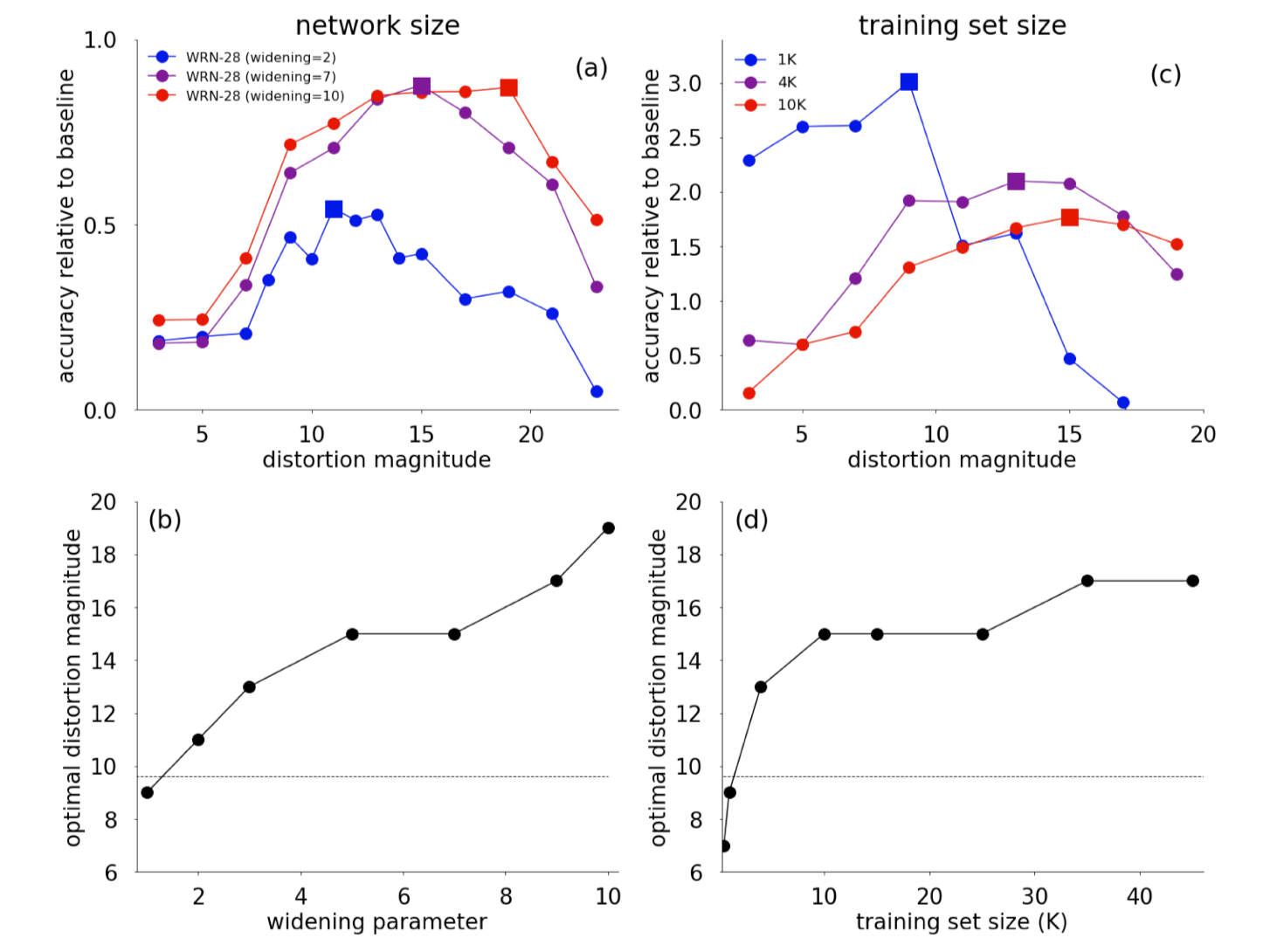
图(a) 表示 Wide-ResNet-28-2、Wide-ResNet-28-7和Wide-ResNet-28-10在不同失真形变程度参数 M 上的精度表现。Models are trained for 200 epochs on 45K training set exampl,正方形表示达到最大精度的失真幅度。
(b)Optimal distortion magnitude across 7 Wide-ResNet-28 architectures with varying widening parameters (k).
(c)Accuracy of Wide-ResNet-28-10 for three training set sizes (1K, 4K, and 10K) across varying distortion magnitudes. Squares indicate the distortion magnitude that achieves the maximal accuracy.
(d)Optimal distortion magnitude across 8 training set sizes. Dashed curves show the scaled expectation value of the distortion magnitude in the AutoAugment policy
从图中增强强度M对数据集和模型大小的依赖性表明,小型代理任务可能会为大型任务提供次优性能指标。
实验结果
作者分别在CIFAR-10, CIFAR-100,SVHN, ImageNet 以及COCO数据集上进行了分类和目标检测等实验验证。
基线模型对比实验

Test accuracy (%) on CIFAR-10, CIFAR-100, SVHN and SVHN core set. Comparisons across default data augmentation (baseline), Population Based Augmentation (PBA) and Fast AutoAugment (Fast AA) , AutoAugment (AA) [5] and proposed RandAugment (RA) .
ImageNet 实验结果

Top-1 and Top-5 accuracies (%) on ImageNet
目标检测实验结果
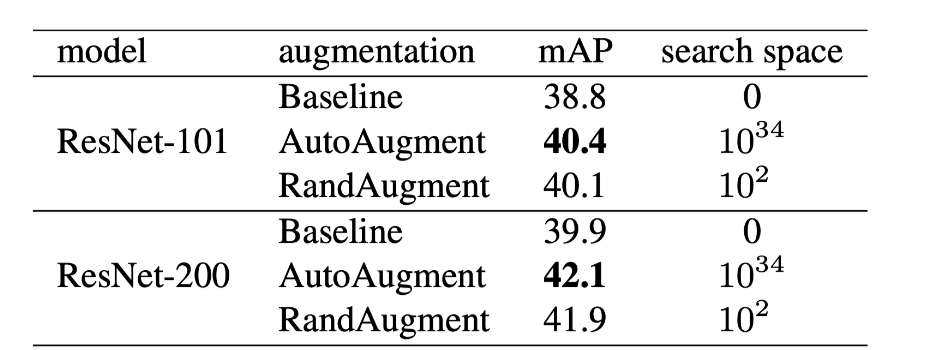
Mean average precision (mAP) on COCO detection task
图像增强方法数量对模型效果影响实验结果
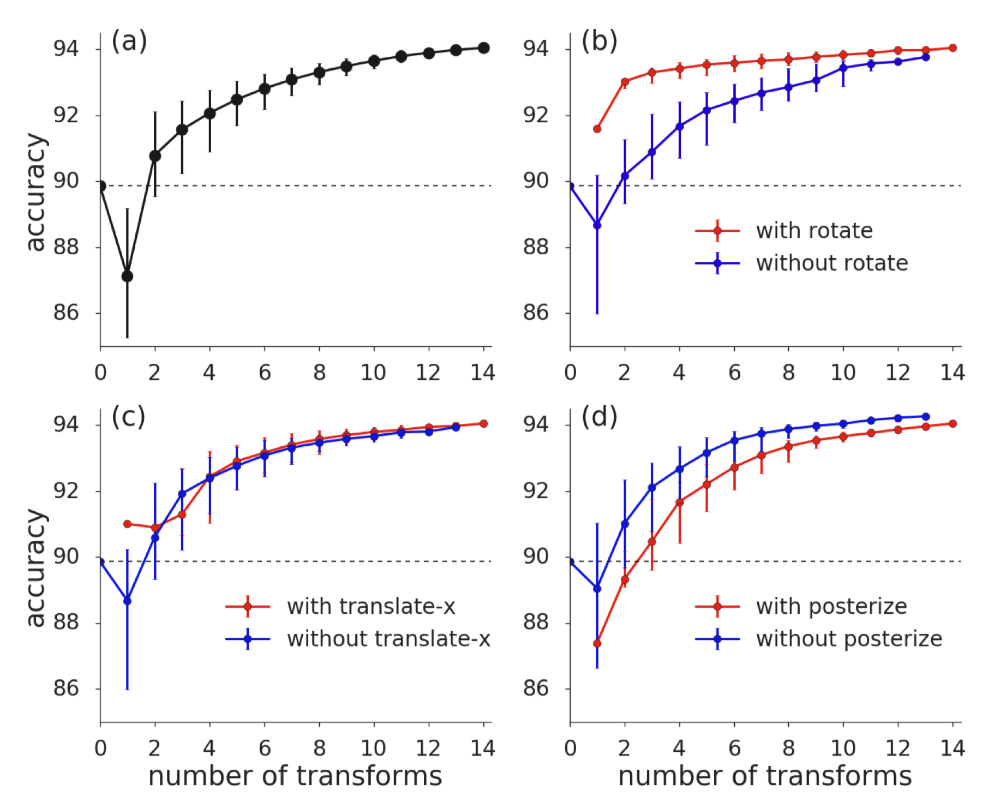
(a) Median accuracy for randomly sampled subsets of transformations.
(b) Median accuracy for subsets with and without the Rotate transformation.
(c) Median accuracy for subsets with and without the translate-x transformation.
(d) Median accuracy for subsets with and without the posterize transformation.
Dashed curves show the accuracy of the model trained without any augmentations.
All panels report median CIFAR-10 validation accuracy for Wide-ResNet-28-2 model architectures trained with RandAugment (N = 3, M = 4) using randomly sampled subsets of transformations. No other data augmentation is included in training. Error bars indicate 30th and 70th percentile.
不同数据增强变换策略对模型的增益效果
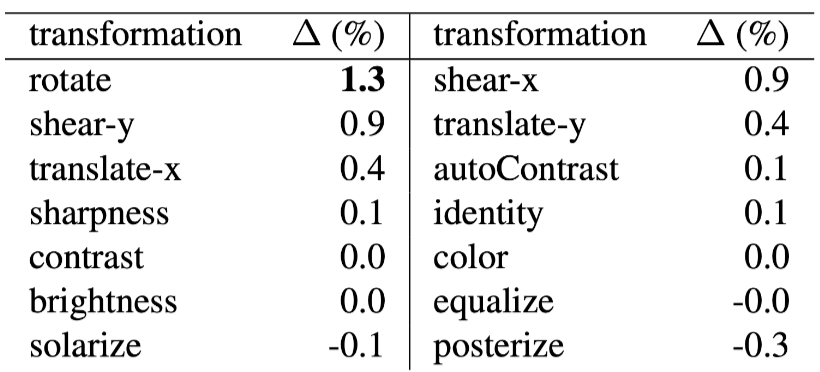
不同规模数据集对增强方法影响的实验结果
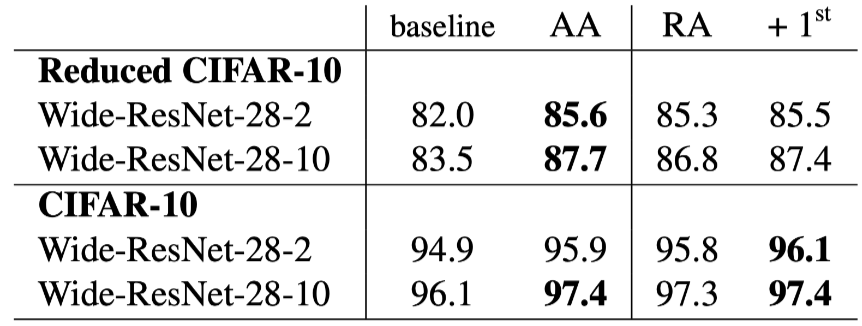
由于RA方法的大多数数据增强变换均是可微的,因此可以通过学习增强变换操作的选择概率来验证其是否可以进一步提高模型效果,对于平均概率选择,学习后的模型效果有略微提升,但是计算成本较高。
Discussion
论文提出的简洁有效,确实显著简化了数据增强的工作难度和效果,可以较好的进行模型迁移,计算成本较小,但存在下一步研究的问题:
这种方法是否可能提高模型的鲁棒性挥着半监督学习性能?
如何在一个给定的模型和任务上选定需要的数据变换方式从而能够提高模型的预测性能?

