Introduction
tf-idf(英语:term frequency–inverse document frequency)是一种用于信息检索与文本挖掘的常用加权技术。
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜寻引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,因特网上的搜寻引擎还会使用基于连结分析的评级方法,以确定文件在搜寻结果中出现的顺序。
TF-IDF有两层意思,一层是”词频”(Term Frequency,缩写为TF),另一层是”逆文档频率”(Inverse Document Frequency,缩写为IDF)。
原理及计算方法
在一份给定的文件里,词频 (term frequency, TF) 指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化(分子一般小于分母 区别于IDF),以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否。)
对于在某一特定文件里的词语 $t_{i}$ 来说,它的重要性可表示为:
以上式子中 $n_{i,j}$ 是该词在文件 $d_{j}$ 中的出现次数,而分母则是在文件 $d_{j}$ 中所有字词的出现次数之和。
逆向文件频率 (inverse document frequency, IDF) 是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。
其中
- $|D|$:语料库中的文件总数
- $|\{j:t_i\in d_j\}|$:包含词语 $t_i$ 的文件数目(即$n_{i,j}\neq 0$的文件数目)如果词语不在数据中,就导致分母为零,因此一般情况下使用 $1+|\{j:t_i\in d_j\}|$
然后
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的tf-idf。因此,tf-idf倾向于过滤掉常见的词语,保留重要的词语。并且一般会预先去除无意义的停用词,进一步增强效果。
使用 sklearn: TfidfVectorizer
TfidfVectorizer可以把原始文本转化为tf-idf的特征矩阵,从而为后续的文本相似度计算,主题模型(如LSI),文本搜索排序等一系列应用奠定基础。
简单的使用如下:
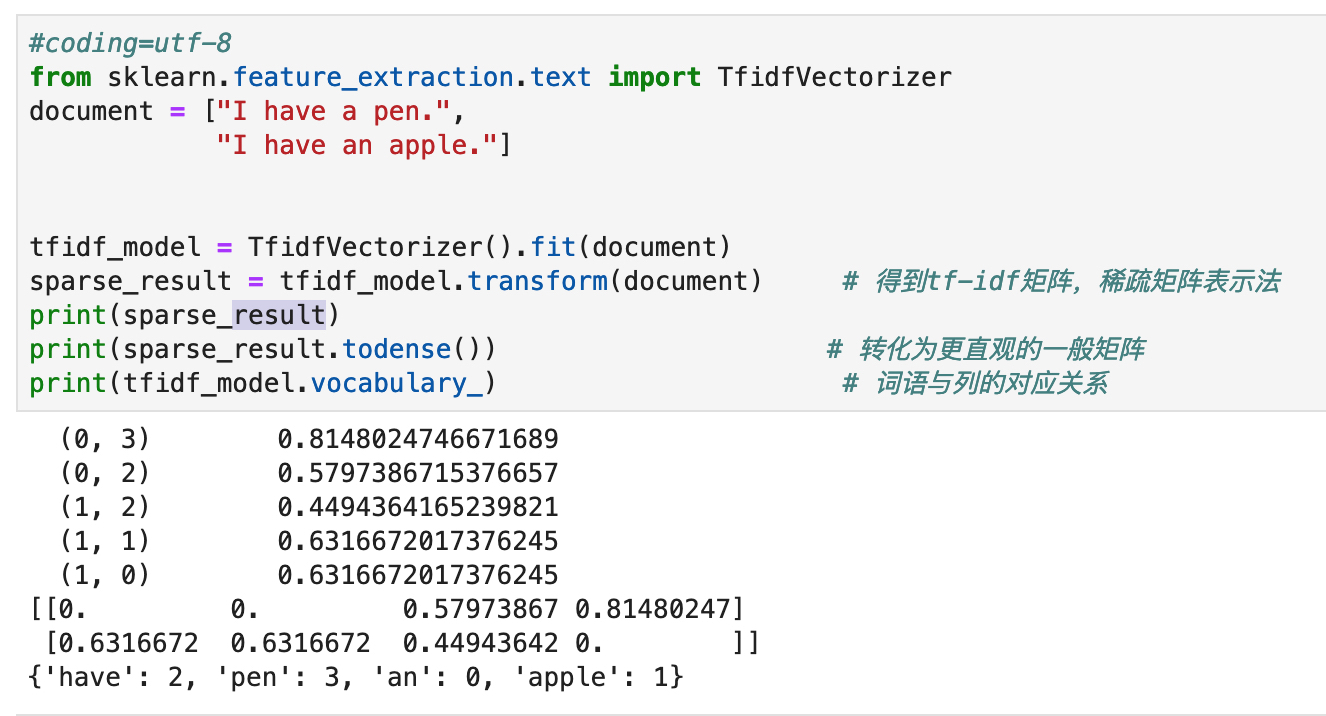
上述输出中,第一次稀疏矩阵的输出,第一列为对应一般矩阵的下标,第二列为值。
第三个字典输出,键为统计的单词,数字为对应的列。比如,apple 对应第一列的。
要把它运用到中文上还需要一些特别的处理
分词
英文可以直接使用空格分割,中文分词则要借助专门的工具,比如结巴分词。
参数
介绍其中几个重要的参数:
token_pattern:这个参数使用正则表达式来分词,其默认参数为r"(?u)\b\w\w+\b",其中的两个\w决定了其匹配长度至少为2的单词max_df/min_df: [0.0, 1.0]内浮点数或正整数, 默认值=1.0。当设置为浮点数时,过滤出现在超过max_df/低于min_df比例的句子中的词语;正整数时,则是超过max_df句句子。这样就可以帮助我们过滤掉出现太多的无意义词语,如下面的”我”就被过滤(虽然这里“我”的排比在文学上是很重要的)。stop_words: list类型,直接过滤指定的停用词。vocabulary: dict类型。只使用特定的词汇,其形式与上面看到的输出vocabulary_相同,也是指定对应关系。这一参数的使用有时能帮助我们专注于一些词语,比如我对本诗中表达感情的一些特定词语(甚至标点符号)感兴趣,就可以设定这一参数,只考虑他们,比如:
1 | tfidf_model5 = TfidfVectorizer(token_pattern=r"(?u)\b\w+\b",vocabulary={"我":0, "呀":1,"!":2}).fit(document) |
实践
Kaggle 的Bag of Words Meets Bags of Popcorn 题目,这个题目是电影评论文本情感分类问题。
拿到预料后,因为是英文语料,首先进行数据清洗和分词预处理,原始语料如下: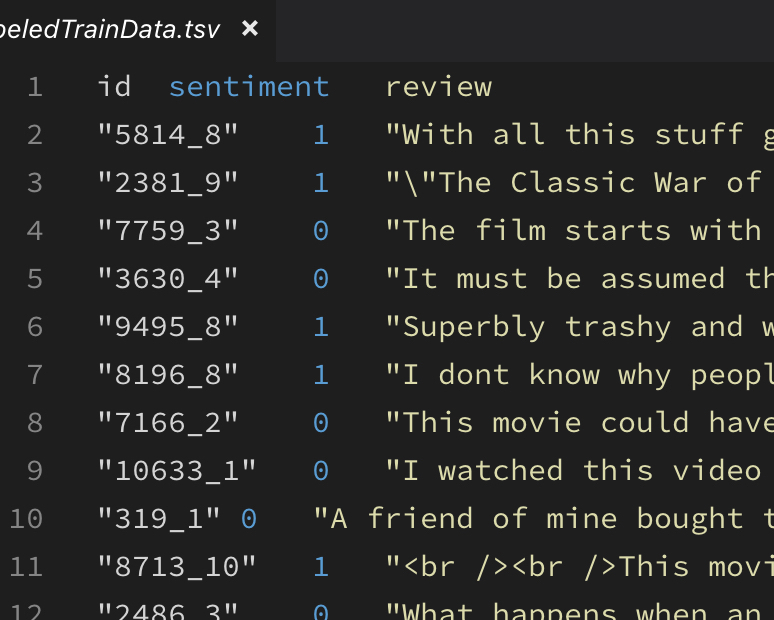
导入库及读入数据:
1 | import pandas as pd |
预处理代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23def review_to_wordlist(review_text):
'''
把IMDB的评论转成词序列
'''
# 去掉涉及的电影名等标签
review_text = re.sub(r'\\.*?\\"', "", review_text)
# 去掉HTML标签
review_text = BeautifulSoup(review_text, "html.parser").get_text()
# 用正则表达式除去非数字、字母外的内容
review_text = re.sub("[^a-zA-Z0-9]"," ", review_text)
# 小写化所有的词,并转成词list
words = review_text.lower().split()
# 返回words
return words
# 获取标签序列和评论数据及测试评论数据
label = train['sentiment']
train_data = []
for i in range(len(train['review'])):
train_data.append(' '.join(review_to_wordlist(train['review'][i])))
test_data = []
for i in range(len(test['review'])):
test_data.append(' '.join(review_to_wordlist(test['review'][i])))
TF-IDF 处理:
1 | tfidf = TFIDF(min_df=2, # 最小支持度为2 |
使用多项式贝叶斯分类器进行分类训练和交叉验证:
1 | model_NB = MNB() |
测试预测输出结果:
1 | test_predicted = np.array(model_NB.predict(test_x)) |
最后结果为 86.692%
准确率显然有待提升,下一步计划使用词向量及神经网络相关技术进一步优化。

