Introduction
人工神经网络求解的实质是寻找合适权重,只有权重合适的神经网络才能发挥出真正的能力,而权重的寻找过程不是靠感觉的,而是一步步优化得来的。由于参数搜索空间非常巨大,训练复杂神经网络因此非常漫长,所以如何快速的经过一定的优化算法确定合适的权重,是一个非常基础而关键的问题。
而在当今求解优化问题过程中一个非常基础重要的概念是梯度。基于此,借助 PyTorch 工具,本文主要介绍如下内容:
- 梯度的概念及性质
- 优化算法与 torch.optim 包
- 实例求解
梯度的概念及性质
梯度的解释及形式化定义
梯度(Gradient)是表征函数上升趋势的量,也即是梯度是表征变化方向最强烈的概念,其大小对应变化方向对应的概念。
比如考虑一座高度在 $ (x, y)$点是 ${\displaystyle H(x,y)} $的山。 ${\displaystyle H}$ 这一点的梯度是在该点坡度(或者说斜度)最陡的方向。梯度的大小告诉我们坡度到底有多陡。
其在张量角度的数学定义如下:
考虑自变量为张量$X$的标量函数$f(X)$。若函数$f(X)$的自变量大小为$S = (s[0],s[1], \cdots, s[n-1])$的张量,则函数$f(X)$的梯度$\nabla_X f(X)$也是一个大小为$S = (s[0],s[1], \cdots, s[n-1])$的张量,并且它的第$I = (i[0],i[1],\cdots,i[n-1])$个元素为函数$f(X)$对元素$x[I]$的偏导数,即是:
简写为 $\nabla f(X)$
具体的,
实标量函数的梯度
- 相对于$n×1$向量$x$的梯度算子记作$\nabla_{\boldsymbol{x}}$定义为:
对向量的梯度
- 以$n×1$实向量$x$为变元的实标量函数$f(x)$相对于$x$的梯度为 —— $n×1$列向量$x$,定义为:
- m维行向量函数 $\boldsymbol{f}(\boldsymbol{x})=[f_1(\boldsymbol{x}),f_2(\boldsymbol{x}),\cdots,f_m(\boldsymbol{x})]$相对于n维实向量x的梯度为 —— $n×m$矩阵,定义为:
对矩阵的梯度
实标量函数 $f(\boldsymbol{A})$相对于$m×n$实矩阵A的梯度为一$m×n$矩阵,简称梯度矩阵,定义为:
梯度的性质
- 梯度的方向就是函数上升的方向
- 梯度的范数越大,函数上升越快
正因为梯度就有上述两个性质,所以只要沿着梯度方向改变自变量,函数的值就有希望变大,沿着梯度方向的反方向改变自变量,函数的值就有希望变小。
因此,梯度对于函数的优化有着极为重要的作用。
计算梯度需要用到的偏导数和梯度的法则,以下法则适用于实标量函数对向量的梯度以及对矩阵的梯度。
- 线性法则:
若 $f(\boldsymbol{A})$ 和 $g(\boldsymbol{A})$ 分别是矩阵A的实标量函数,$c_1$和$c_2$为实常数,则:
一般化形式简写为:
- 乘积法则
若 $f(\boldsymbol{A})$ ,$g(\boldsymbol{A})$ 和 $h(\boldsymbol{A})$ 分别是矩阵A的实标量函数,则
一般化形式简化写为:
- 链式法则
若A为m×n矩阵,且 $y=f(\boldsymbol{A})$ 和 $g (y)$分别是以矩阵A和标量y为变元的实标量函数,则:
一般化写作:
优化算法与 torch.optim 包
梯度下降算法
上面我们讲到梯度的相关性质,由此可以作出如下的简单推论:对于某个自变量,如果自变量顺着梯度的方向改变那么函数值就有可能变大,如果自变量逆着梯度方向改变,那么函数值就有可能变小。梯度下降算法就是基于这一基本原理求解函数最小值的。
梯度下降算法的相关概念定义:
- 步长(Learning rate):步长决定了在梯度下降迭代的过程中,每一步沿梯度负方向前进的长度。
- 特征(feature):指的是样本中输入部分,比如2个单特征的样本$(x^{(0)},y^{(0)}),(x^{(1)},y^{(1)})$,则第一个样本特征为$x^{(0)}$,第一个样本输出为$y^{(0)}$。
- 假设函数(hypothesis function):在监督学习中,为了拟合输入样本,而使用的假设函数,记为$h_{\theta}(x)$。比如对于单个特征的m个样本$(x^{(i)},y^{(i)})(i=1,2,…m)$,可以采用拟合函数如下:$h_{\theta}(x) = \theta_0+\theta_1x$。
损失函数(loss function):为了评估模型拟合的好坏,通常用损失函数来度量拟合的程度。损失函数极小化,意味着拟合程度最好,对应的模型参数即为最优参数。在线性回归中,损失函数通常为样本输出和假设函数的差取平方。比如对于m个样本$(x_i,y_i)(i=1,2,…m)$,采用线性回归,损失函数为:
其中$x_i$表示第i个样本特征,$y_i$表示第i个样本对应的输出,$h_θ(x_i)$为假设函数。
更多关于 gradient descent 算法的内容见此文章
PyTorch 实现
torch.optim包内包含了一系列的优化算法,其中包含了optim.SGD就实现了梯度下降算法。
如下示例是求解函数 $f(x) = -(\cos^2x[0]+\cos^2x[1])^2$ 最小值的代码:
1 | from math import pi |
运行结果如下:
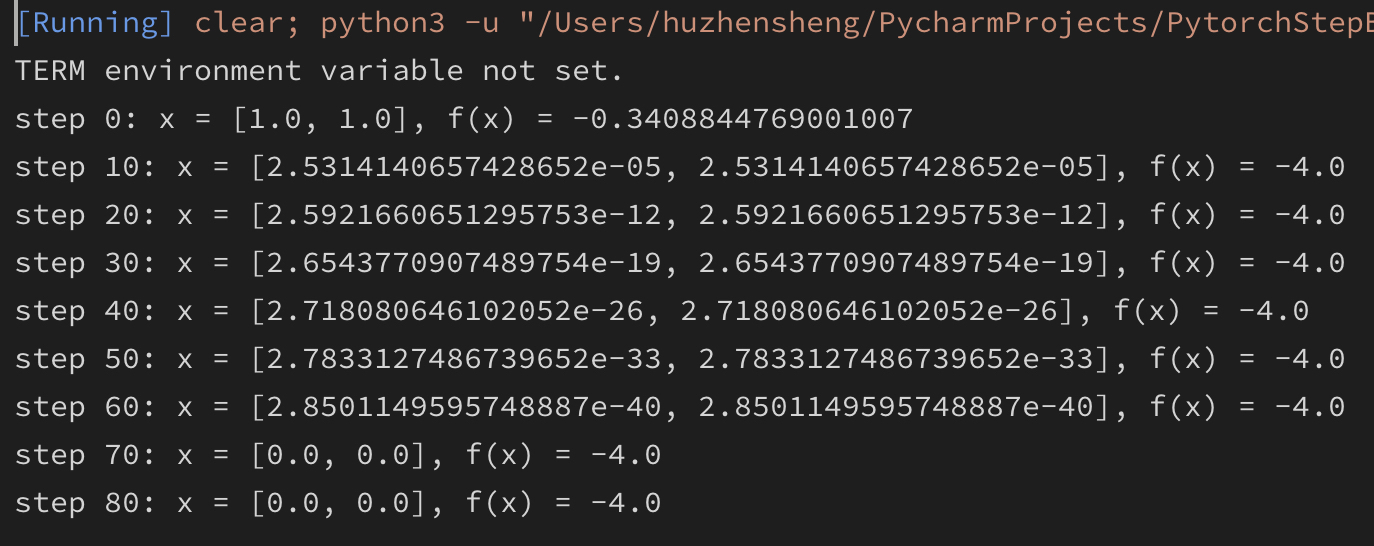
上述代码首先定义了要求梯度的自变量 x 及其初始值1.0,1.0,requires_grad=True表示要对此变量求梯度。
然后定义了关于自变量 x 的函数f,并定义了优化器实例 optimizer,使用的优化方法是 随机梯度下降方法,学习率是 0.1。
最后定义了一个循环,再次循环内:
首先调用了优化器实例的函数zero_grad(),将其内部存储的之前的梯度值清零,之后利用f.backward()求解梯度值,再利用optimizer.step()根据优化器的优化算法更新x的值,最后将新更新后的x值代入到函数f中,更新函数值。直至循环结束。
上述的运算过程中,首先计算当前位置的梯度值,根据此梯度值更新下一步变量的值,再将更新后的变量值代入目标函数表达式,求出下一步的函数值,再次循环上述步骤。由于梯度的相关性质,只要更新算法得当,最后就会得到一个合适的结果。
梯度下降算法存在的问题及解决
上面我们定义的梯度下降算法的基本形式,对于最基本的梯度下降算法,在第 t (t=1,2,3,4,…) 步迭代的时候,需要定义学习率 $\eta_t = \eta$,计算梯度$G_{t-1} = \nabla f(X_{t-1})$,并按照下面的式子来更新自变量:
其中 $V_i = G_{t-1}$。
上面的算法存在明显的问题:
- 容易陷入局部极小值,甚至陷入鞍点,凡是梯度值为 0 的地方,该算法就陷入停滞,但是梯度值为0并不一定恰好是全局最小值。
- 学习率选取的不当,会导致结果在极小值附近左右震荡而无法有效接近最优点
对于上述的两个两个问题都有对应的解决办法:
前一个问题使用“动量”,后一个问题使用“动态调整学习率”。
动量引入
动量听起来很高深,其实放在物理上的理解就是增加“惯性势能”,为梯度增加一个惯性值,当梯度到达一个为零的点的时候,回顾其之前的变化过程,如果之前一直是以比较陡峭的速度下降,那么落到该点的时候给其在改点的梯度值加上一个额外的惯性,即是动量,这样它就不是零了,就能继续向前行走,走出鞍点、甚至走出局部最小值。
一般而言,动量的表达式可以是:
其中,$\rho 和 \rho^\prime$是预设的函数,$V_t$将用于更新$X_{t-1}$,入上述梯度下降算法的基本形式中:
学习率的动态调整
理想情况下学习率的变化是这样的:在迭代刚开始的时候学习率比较大,从而让自变量的变化尽可能的大,然后快接近最优点的时候,学习率变得比较小,从而自变量也可以慢慢接近最优点不至于跳过去来回震荡。
这就要求能够让学习率动态调整,在迭代过程中变化,而且对于多元素的自变量的学习率不一样,有必要为张量的不同元素设置不同的学习率。
其中一个实现方法就是根据历次梯度的各元素平滑的二范数。比如,对于自变量 X 中的元素$X[I]$,设其在第 t 次的梯度 $G_t = \nabla f(X_t)$处的第 I 个元素为 g[I], 则可以让第 t 次迭代作用于自变量 $x_{t-1}[I]$的学习率为:
其中 $l 和 \epsilon$ 是预设的,随着迭代的进行,分母不断变大,学习率不断的变小,一定程度上实现了学习率的动态调整。
但是上述的调整还是不尽合理的,因为按照正常的逻辑,距离当前迭代位置的远近对于学习率变化的贡献不应该是一致的,而且有可能学习率的变化不一定是越来越小。
不过上述的式子提供了一种思路,另外一个根据距离远近调整的方法是结合“指数权重平均”的算法来实现的。
更多关于学习率调整的思路可以参看这篇文章:梯度下降学习率的设定策略
小结
根据以上对梯度更新、学习率相关的介绍,研究演化了各种优化器,具体的可以参考这篇论文器,具体的可以参考这篇论文An overview of gradient descent optimizati
中文文章参考:深度学习——优化器算法Optimizer详解(BGD、SGD、MBGD、Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam)
实例
主要是求 himmelblau 函数最小值。
该函数的图像如下所示: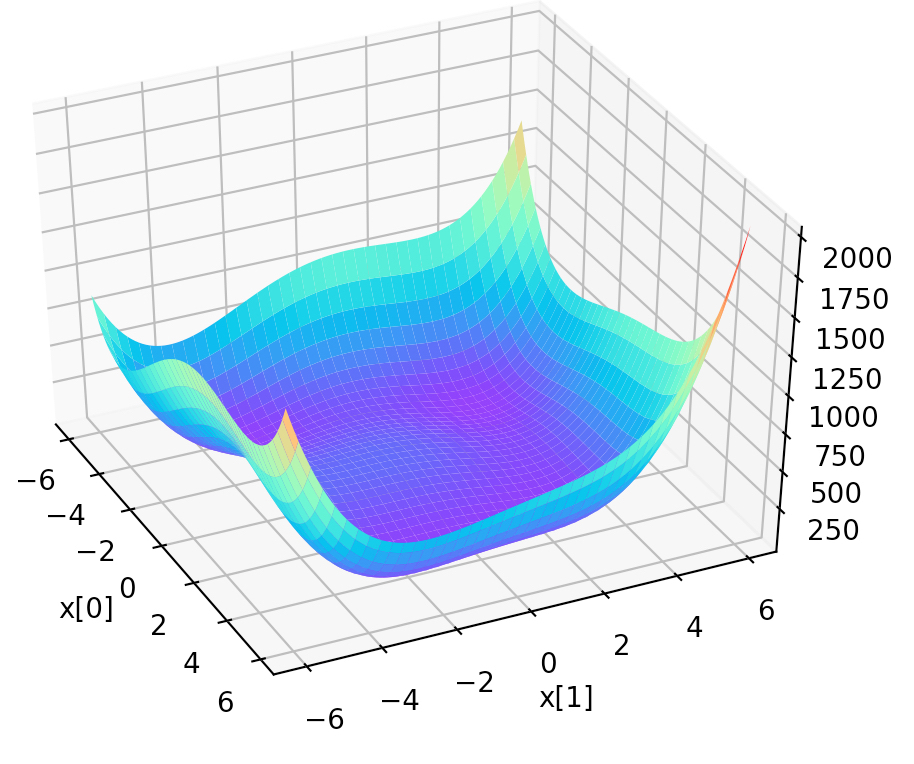
该函数有四个极小值点。
使用 adam 优化器的代码如下
1 | import numpy as np |

