引言
早上上班的路上读《社会心理学》里面有一段话,觉得不错,摘在这里。
我们人类总是有一种不可抑制的冲动,想要解释行为,对其归因,以使其变得次序井然.具有可预见性,使一切尽在掌握之中。你我对于类似的情境却可能表现出截然不同的反应,这是因为我们的想法不同。我们对朋友的责难做何反应,取决于我们对其所做的解释,取决于我们是把它归咎于朋友的敌意行为,还是归结于他糟糕的心情。
从某种角度来说,我们都是天生的科学家。我们解释着他人的行为,通常足够快也足够准确,以适应我们日常生活的需要。当他人的行为具有一致性而且与众不同时,我们会把其行为归因于他们的人格。例如。如果你发现一个人说话总是对人冷嘲热讽.你可能就会推断此人秉性不良,然后便设法尽量避免与他的接触。
当然这是指更大范围内的人类心理,在对数据和模型的痴迷上,人类的欲望显然也是强烈的,人类总是想尽一切的办法打破现有的桎梏,在创造了更多的不确定性之后,期望通过对数据的把控和预测以看到更确切的未来。
这次我们来从矩阵和向量的角度来解释最小二乘法及非线性的模拟建模。
LS 的矩阵推导
继续使用上一次的方程式并将其改写成矩阵的形式如下:
代入最小二乘损失函数,得到结果为:
式 2.2 到式 2.3 的证明忽略。
其中 $X$ 、$W$ 和 $T$ 为:
对上述 2.3 展开,得到下面的表达式:
为了得到最小值,需要得到 $\mathcal{L}$的拐点(极小值)一致的向量$w$的值,这里一样是求 $\mathcal{L}$ 关于 $w$ 的偏导数,并令其为 0,可以代入上述的矩阵进行求解,也可以使用一些恒等式来直接化简:
得到的表达式如下:
从而得到使损失最小的$w$值,$\hat w$ 的矩阵公式为:
根据此公式解出的值与上次用标量形式解出的是一样的。
线性模型的非线性响应
前面我们所假设的是拟合函数是一次函数,但是可以明显的看出拟合效果并不好,所以需要往更高次的多项式延伸,假如是二次的话,那么可以表示为:
更一般的,扩展 $x$ 的幂次到任意任意阶的多项式函数,对于一个 K 阶多项式,可以扩展数据矩阵为:
函数表达为更一般的形式:
其解一样适用于式 $2.5$
可以求得其八阶线性拟合结果如下:
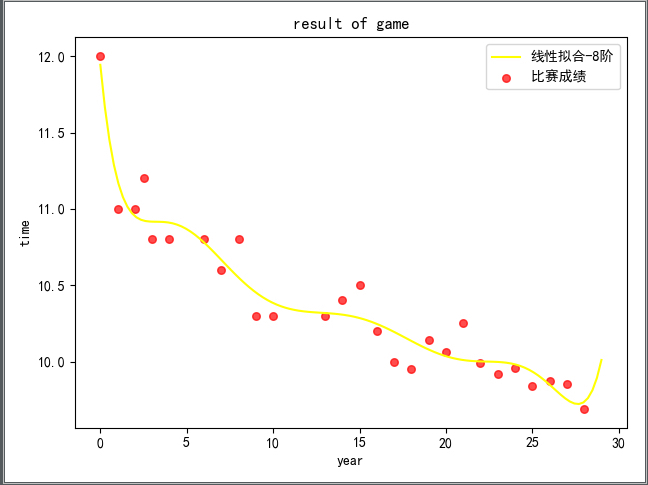
代码如下:
1 | # -*- coding: utf-8 -* |
过拟合与验证
从上次的一阶线性拟合到现在的八阶拟合,从直观上看,八阶的拟合效果比一阶的明显好很多,但是我们做拟合的根本目的是为了做预测,不是纯粹为了拟合而拟合,因为理论上说,一般对于 n 个点,可以拟合 n-1 次多项式以便完全通过这些点。但是这样子的拟合结果对于预测而言可能是极其差的。
那么如何衡量呢?
和拟合是一样的思想,看模型在泛化问题时候的表现,即是在预测验证数据上的表现,如果其损失很小,那么可以认为这个模型的预测能力不错。
验证数据
克服过拟合问题的一般方法是使用第二个数据集,即是验证集。用其来验证模型的预测性能,验证集可以是单独提供的,也可以从原始训练集中拿出来的。
从验证集计算的损失对于验证集数据的选择敏感,如果验证集非常小,那就更加困难了,而交叉验证是一个有效使用现有数据集的方法。
一般是 K 折交叉验证,当 K = N 的时候,及 K 恰好是等于数据集中的可观测数据的数量,每个观测数据依次拿出用作测试其他 N-1 个对象训练得到的模型,其又叫 留一交叉验证 (Leave-One-Out Cross Validation, LOOCV),对于 LOOCV 的均方验证为:
其中 $\hat{w}_{-n}$ 是除去第 n 个训练样例的参数估计值。
应用实例及代码实现
首先定义一个带噪声的函数,并用其生成 100 个随机数据点作为训练数据,生成 1000 个随机数据点作为测试数据,生成数据点的 $x$ 范围是 [-5,5], 表达式如下,其中噪声$\mathcal {N}$ 符合正态分布
使用如上的矩阵式,对数据进行不同阶数的拟合,得到的结果如下:
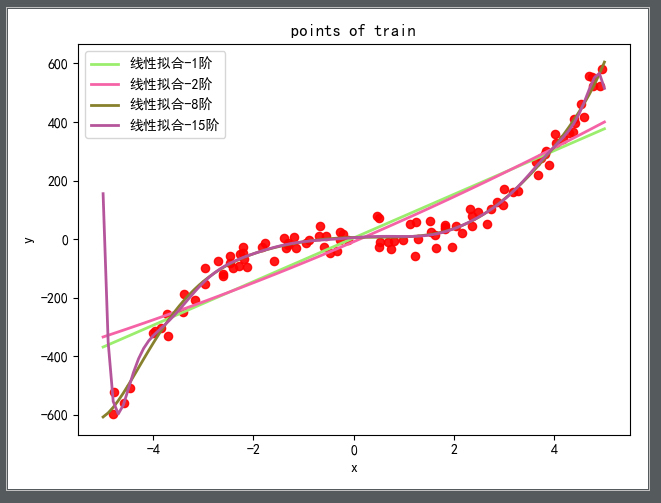
然后,分别对比训练损失、测试损失及使用 LOOCV 方法拟合及其损失随着阶数增高而变化的曲线如下图所示:
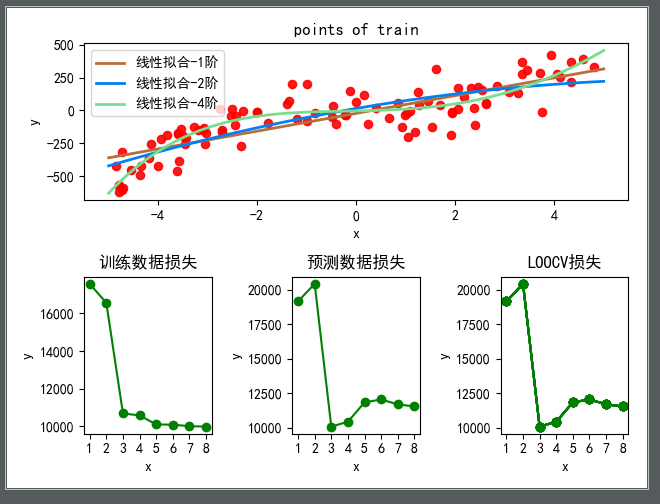
可以从图中看出,在 3 阶的时候,测试损失和 LOOCV 损失达到最小,且 3 阶拟合之后训练损失不明显,但是测试损失明显增高,即产生了过拟合的现象。
实现代码如下:
1 | # -*- coding: utf-8 -* |
Next
下一次是真正入门啦,将之前说过的贝叶斯定理应用于机器学习,和你分享如何使用朴素的贝叶斯方法来进行简单的分类工作,比如识别手写数字,新闻素材的主题分类。(具体是挖那个主题的坑,还不知道

